
DP-100 문제 26
AutoMLConfig 클래스를 사용하여 최대 10번의 모델 학습 반복을 포함하는 자동화된 머신 러닝 작업을 정의하는 실험을 실행합니다. 이 작업은 정확도라는 메트릭을 기반으로 가장 성능이 좋은 모델을 찾으려고 시도합니다.
다음 코드로 실험을 제출하세요.
자동화된 머신 러닝 작업에서 생성된 최상의 모델을 반환하는 Python 코드를 만들어야 합니다. 어떤 코드 세그먼트를 사용해야 합니까?
다음 코드로 실험을 제출하세요.
자동화된 머신 러닝 작업에서 생성된 최상의 모델을 반환하는 Python 코드를 만들어야 합니다. 어떤 코드 세그먼트를 사용해야 합니까?
DP-100 문제 27
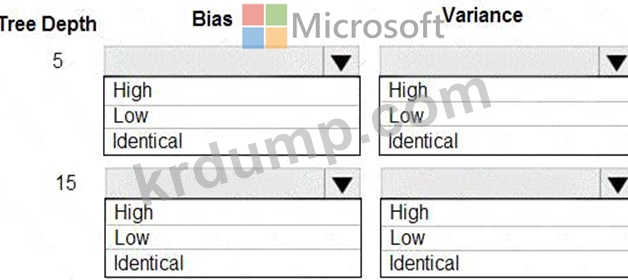
당신은 결정 트리 알고리즘을 사용하고 있습니다. 당신은 트리 깊이가 다음과 같을 때 잘 일반화되는 모델을 훈련했습니다.
10.
다양한 트리 깊이 값을 사용하여 모델의 편향 및 분산 속성을 선택해야 합니다.
각 나무 깊이에 대해 어떤 속성을 선택해야 합니까? 답하려면 답변 영역에서 적절한 옵션을 선택하세요.
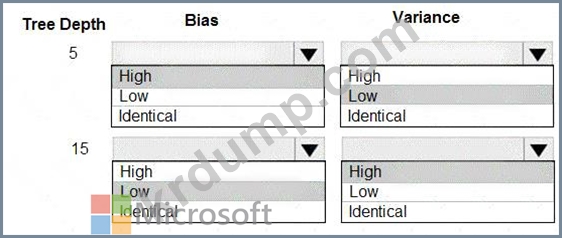
10.
다양한 트리 깊이 값을 사용하여 모델의 편향 및 분산 속성을 선택해야 합니다.
각 나무 깊이에 대해 어떤 속성을 선택해야 합니까? 답하려면 답변 영역에서 적절한 옵션을 선택하세요.

DP-100 문제 28
AccessibilityToHighway 열에서 누락된 데이터를 바꿔야 합니다.
Clean Missing Data 모듈을 어떻게 구성해야 합니까? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고사항: 정답 하나당 1점입니다.

Clean Missing Data 모듈을 어떻게 구성해야 합니까? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고사항: 정답 하나당 1점입니다.

DP-100 문제 29
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 이 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 두 개 이상의 정답이 있을 수 있고, 다른 세트에는 정답이 없을 수 있습니다.
이 섹션의 질문에 답한 후에는 다시 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 나타나지 않습니다.
작업 영역에서 Azure Machine Learning 서비스 데이터 저장소를 만듭니다. 데이터 저장소에는 다음 파일이 포함되어 있습니다.
* /데이터/2018/Q1.csv
* /데이터/2018/Q2.csv
* /데이터/2018/Q3.csv
* /데이터/2018/Q4.csv
* /데이터/2019/Q1.csv
모든 파일은 다음 형식으로 데이터를 저장합니다.
아이디,f1,f2i
1,1.2,0
2,1,1,
1 3,2.1,0
다음 코드를 실행합니다.

다음 코드를 사용하여 training_data라는 데이터 세트를 만들고 모든 파일의 데이터를 단일 데이터 프레임으로 로드해야 합니다.

해결책: 다음 코드를 실행하세요.

해결책이 목표를 충족하는가?
이 섹션의 질문에 답한 후에는 다시 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 나타나지 않습니다.
작업 영역에서 Azure Machine Learning 서비스 데이터 저장소를 만듭니다. 데이터 저장소에는 다음 파일이 포함되어 있습니다.
* /데이터/2018/Q1.csv
* /데이터/2018/Q2.csv
* /데이터/2018/Q3.csv
* /데이터/2018/Q4.csv
* /데이터/2019/Q1.csv
모든 파일은 다음 형식으로 데이터를 저장합니다.
아이디,f1,f2i
1,1.2,0
2,1,1,
1 3,2.1,0
다음 코드를 실행합니다.
다음 코드를 사용하여 training_data라는 데이터 세트를 만들고 모든 파일의 데이터를 단일 데이터 프레임으로 로드해야 합니다.
해결책: 다음 코드를 실행하세요.
해결책이 목표를 충족하는가?
DP-100 문제 30
팀 데이터 과학 환경을 구축할 계획입니다. 머신 러닝 파이프라인에서 모델을 훈련하기 위한 데이터 크기는 20GB가 넘습니다.
다음과 같은 요구 사항을 충족합니다.
* 모델은 Caffe2 또는 Chainer 프레임워크를 사용하여 구축되어야 합니다.
* 데이터 과학자는 연결된 네트워크 환경과 연결되지 않은 네트워크 환경 모두에서 개인 기기에서 머신 러닝 파이프라인을 구축하고 모델을 학습하기 위해 데이터 과학 환경을 사용할 수 있어야 합니다.
개인 기기는 네트워크에 연결된 경우 머신 러닝 파이프라인 업데이트를 지원해야 합니다.
데이터 과학 환경을 선택해야 합니다.
어떤 환경을 사용해야 하나요?
다음과 같은 요구 사항을 충족합니다.
* 모델은 Caffe2 또는 Chainer 프레임워크를 사용하여 구축되어야 합니다.
* 데이터 과학자는 연결된 네트워크 환경과 연결되지 않은 네트워크 환경 모두에서 개인 기기에서 머신 러닝 파이프라인을 구축하고 모델을 학습하기 위해 데이터 과학 환경을 사용할 수 있어야 합니다.
개인 기기는 네트워크에 연결된 경우 머신 러닝 파이프라인 업데이트를 지원해야 합니다.
데이터 과학 환경을 선택해야 합니다.
어떤 환경을 사용해야 하나요?