
DP-100 문제 1
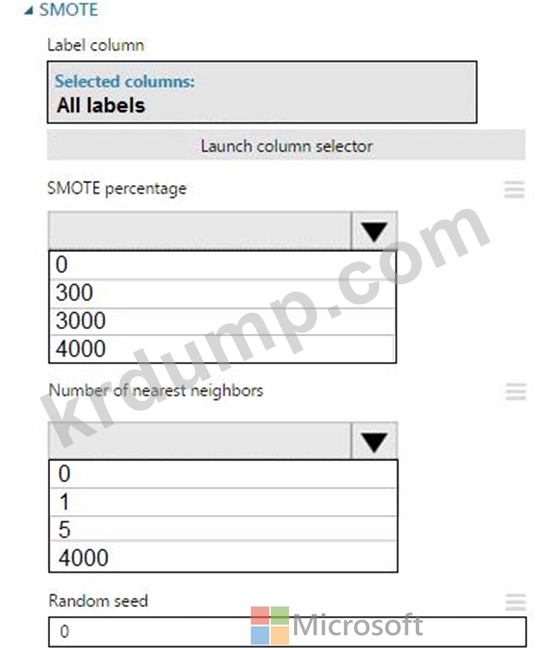
Azure Machine Learning Studio에서 실험을 만듭니다. 10,000개의 행이 포함된 교육 데이터 세트를 추가합니다. 처음 9,000개의 행은 클래스 0(90퍼센트)을 나타냅니다.
나머지 1,000개 행은 클래스 1(10%)을 나타냅니다.
훈련 세트는 두 클래스 간의 불균형입니다. 5개의 데이터 행을 사용하여 클래스 1의 훈련 예제 수를 4,000개로 늘려야 합니다. 실험에 Synthetic Minority Oversampling Technique(SMOTE) 모듈을 추가합니다.
모듈을 구성해야 합니다.
어떤 값을 사용해야 합니까? 대답하려면 답변 영역의 대화 상자에서 적절한 옵션을 선택합니다.
참고사항: 정답 하나당 1점입니다.
나머지 1,000개 행은 클래스 1(10%)을 나타냅니다.
훈련 세트는 두 클래스 간의 불균형입니다. 5개의 데이터 행을 사용하여 클래스 1의 훈련 예제 수를 4,000개로 늘려야 합니다. 실험에 Synthetic Minority Oversampling Technique(SMOTE) 모듈을 추가합니다.
모듈을 구성해야 합니다.
어떤 값을 사용해야 합니까? 대답하려면 답변 영역의 대화 상자에서 적절한 옵션을 선택합니다.
참고사항: 정답 하나당 1점입니다.

DP-100 문제 2
동료가 다음 코드를 사용하여 Machine Learning 서비스 작업 공간에 데이터 저장소를 등록합니다.
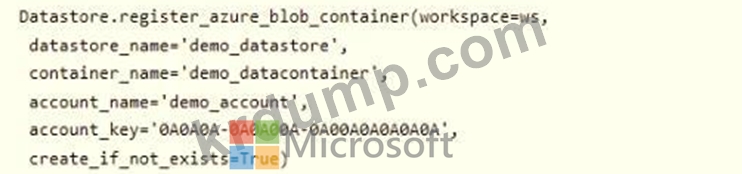
노트북에서 데이터 저장소에 액세스하려면 코드를 작성해야 합니다.

노트북에서 데이터 저장소에 액세스하려면 코드를 작성해야 합니다.

DP-100 문제 3
분류 모델을 학습하려는 데이터가 포함된 CSV(쉼표로 구분된 값) 파일이 있습니다.
Azure Machine Learning Studio에서 자동화된 머신 러닝 인터페이스를 사용하여 분류 모델을 학습합니다. 작업 유형을 분류로 설정합니다.
자동화된 머신 러닝 프로세스가 선형 모델만 평가하는지 확인해야 합니다.
어떻게 해야 할까요?
Azure Machine Learning Studio에서 자동화된 머신 러닝 인터페이스를 사용하여 분류 모델을 학습합니다. 작업 유형을 분류로 설정합니다.
자동화된 머신 러닝 프로세스가 선형 모델만 평가하는지 확인해야 합니다.
어떻게 해야 할까요?



DP-100 문제 4
제공된 학습 세트를 사용하여 이진 분류 모델을 구축하고 있습니다.
두 클래스 간의 훈련 세트가 불균형합니다.
데이터 불균형을 해결해야 합니다.
이 목표를 달성할 수 있는 세 가지 가능한 방법은 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답은 1점입니다.
두 클래스 간의 훈련 세트가 불균형합니다.
데이터 불균형을 해결해야 합니다.
이 목표를 달성할 수 있는 세 가지 가능한 방법은 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답은 1점입니다.
DP-100 문제 5
Azure Machine Learning 작업 공간을 관리합니다. Azure Machine Learning Python SDK v2로 학습 작업을 제출합니다. 모델을 학습할 때 MLflow를 사용하여 메트릭, 모델 매개변수 및 mode! 아티팩트를 자동으로 기록해야 합니다.
다음 코드 세그먼트를 작성하여 시작하세요.

다음 각 문장에 대해 문장이 사실이라면 예를 선택하세요. 그렇지 않으면 아니요를 선택하세요.

다음 코드 세그먼트를 작성하여 시작하세요.
다음 각 문장에 대해 문장이 사실이라면 예를 선택하세요. 그렇지 않으면 아니요를 선택하세요.

