
DP-700 문제 31
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 하나입니다. 각 문제는 명시된 목표를 충족할 수 있는 고유한 답안을 포함하고 있습니다. 일부 문제 세트에는 정답이 두 개 이상 있을 수 있고, 다른 문제 세트에는 정답이 없을 수 있습니다.
이 섹션의 질문에 답변한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 해당 질문은 복습 화면에 표시되지 않습니다.
Stream과 Reference라는 두 테이블이 포함된 KQL 데이터베이스가 있습니다. Stream에는 다음 형식의 스트리밍 데이터가 포함되어 있습니다.
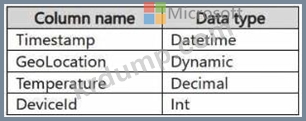
참고문헌에는 다음 형식의 참고자료가 포함되어 있습니다.
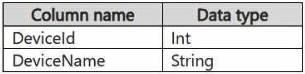
두 표 모두 수백만 개의 행을 포함하고 있습니다.
다음과 같은 KQL 쿼리셋이 있습니다.

KQL 쿼리셋을 실행하는 데 걸리는 시간을 줄여야 합니다.
해결 방법: make_list() 함수를 출력 열에 추가합니다.
이것이 목표를 달성하는가?
이 섹션의 질문에 답변한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 해당 질문은 복습 화면에 표시되지 않습니다.
Stream과 Reference라는 두 테이블이 포함된 KQL 데이터베이스가 있습니다. Stream에는 다음 형식의 스트리밍 데이터가 포함되어 있습니다.
참고문헌에는 다음 형식의 참고자료가 포함되어 있습니다.
두 표 모두 수백만 개의 행을 포함하고 있습니다.
다음과 같은 KQL 쿼리셋이 있습니다.
KQL 쿼리셋을 실행하는 데 걸리는 시간을 줄여야 합니다.
해결 방법: make_list() 함수를 출력 열에 추가합니다.
이것이 목표를 달성하는가?
DP-700 문제 32
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 하나입니다. 각 문제는 명시된 목표를 충족할 수 있는 고유한 답안을 포함하고 있습니다. 일부 문제 세트에는 정답이 두 개 이상 있을 수 있고, 다른 문제 세트에는 정답이 없을 수 있습니다.
이 섹션의 질문에 답변한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 해당 질문은 복습 화면에 표시되지 않습니다.
KQL 데이터베이스의 Bike_Location이라는 테이블에 데이터를 로드하는 Fabric 이벤트 스트림이 있습니다. 해당 테이블에는 다음 열이 포함되어 있습니다.
데이터를 사용할 수 있도록 준비하려면 변환 및 필터 논리를 적용해야 합니다. 솔루션은 No_Bikes가 15 이상일 때 Sands End라는 동네에 대한 데이터를 반환해야 합니다. 결과는 No_Bikes를 기준으로 오름차순으로 정렬되어야 합니다.
해결 방법: 다음 코드 세그먼트를 사용합니다.

이것이 목표를 달성하는가?
이 섹션의 질문에 답변한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 해당 질문은 복습 화면에 표시되지 않습니다.
KQL 데이터베이스의 Bike_Location이라는 테이블에 데이터를 로드하는 Fabric 이벤트 스트림이 있습니다. 해당 테이블에는 다음 열이 포함되어 있습니다.
데이터를 사용할 수 있도록 준비하려면 변환 및 필터 논리를 적용해야 합니다. 솔루션은 No_Bikes가 15 이상일 때 Sands End라는 동네에 대한 데이터를 반환해야 합니다. 결과는 No_Bikes를 기준으로 오름차순으로 정렬되어야 합니다.
해결 방법: 다음 코드 세그먼트를 사용합니다.
이것이 목표를 달성하는가?
DP-700 문제 33
귀사에는 Fabric을 사용할 계획인 Team1, Team2, Team3이라는 세 개의 새로 구성된 데이터 엔지니어링 팀이 있습니다. 각 팀의 페르소나는 다음과 같습니다.
* Team1은 현재 Microsoft Power BI를 사용하는 팀원들로 구성되어 있습니다. 이 팀은 로우코드 방식을 사용하여 데이터를 변환하고자 합니다.
* Team2는 Python 프로그래밍 경험이 있는 멤버들로 구성되어 있습니다. 이 팀은 PySpark 코드를 사용하여 데이터를 변환하고자 합니다.
* Team3은 현재 Azure Data Factory를 사용하는 구성원으로 구성되어 있습니다. 팀은 최소한의 노력으로 원본 환경과 싱크 환경 간에 데이터를 이동하고자 합니다.
팀의 현재 페르소나를 기반으로 팀에 적합한 도구를 추천해야 합니다.
각 팀에 어떤 것을 추천해야 할까요? 답변란에서 적절한 항목을 선택해 답변하세요.
참고: 정답 하나당 1점입니다.

* Team1은 현재 Microsoft Power BI를 사용하는 팀원들로 구성되어 있습니다. 이 팀은 로우코드 방식을 사용하여 데이터를 변환하고자 합니다.
* Team2는 Python 프로그래밍 경험이 있는 멤버들로 구성되어 있습니다. 이 팀은 PySpark 코드를 사용하여 데이터를 변환하고자 합니다.
* Team3은 현재 Azure Data Factory를 사용하는 구성원으로 구성되어 있습니다. 팀은 최소한의 노력으로 원본 환경과 싱크 환경 간에 데이터를 이동하고자 합니다.
팀의 현재 페르소나를 기반으로 팀에 적합한 도구를 추천해야 합니다.
각 팀에 어떤 것을 추천해야 할까요? 답변란에서 적절한 항목을 선택해 답변하세요.
참고: 정답 하나당 1점입니다.


DP-700 문제 34
Amazon S3 버킷의 데이터 사용이 기술적 요구 사항을 충족하는지 확인해야 합니다.
어떻게 해야 하나요?
어떻게 해야 하나요?
DP-700 문제 35
핫스팟
Workspace1_DEV라는 Fabric 작업 공간이 있으며 여기에는 다음 항목이 포함되어 있습니다.
10개의 보고서
네 개의 노트북
세 개의 호수 주택
두 개의 데이터 파이프라인
두 개의 Dataflow Gen1 데이터 흐름
3개의 Dataflow Gen2 데이터 흐름
각각 예약된 새로 고침 정책이 있는 5개의 의미 모델
Workspace1_DEV의 항목을 Workspace1_TEST라는 새 작업 공간으로 이동하려면 Pipeline1이라는 배포 파이프라인을 만듭니다.
Workspace1_DEV의 모든 항목을 Workspace1_TEST에 배포합니다.
다음 각 문장에 대해, 문장이 사실이라면 '예'를 선택하세요. 그렇지 않으면 '아니요'를 선택하세요.
참고: 정답 하나당 1점입니다.

Workspace1_DEV라는 Fabric 작업 공간이 있으며 여기에는 다음 항목이 포함되어 있습니다.
10개의 보고서
네 개의 노트북
세 개의 호수 주택
두 개의 데이터 파이프라인
두 개의 Dataflow Gen1 데이터 흐름
3개의 Dataflow Gen2 데이터 흐름
각각 예약된 새로 고침 정책이 있는 5개의 의미 모델
Workspace1_DEV의 항목을 Workspace1_TEST라는 새 작업 공간으로 이동하려면 Pipeline1이라는 배포 파이프라인을 만듭니다.
Workspace1_DEV의 모든 항목을 Workspace1_TEST에 배포합니다.
다음 각 문장에 대해, 문장이 사실이라면 '예'를 선택하세요. 그렇지 않으면 '아니요'를 선택하세요.
참고: 정답 하나당 1점입니다.

