
DP-203 문제 101
ADF1이라는 Azure Data Factory 인스턴스와 WS1 및 WS2라는 두 개의 Azure Synapse Analytics 작업 영역이 있습니다.
ADF1에는 다음 파이프라인이 포함되어 있습니다.
P1: 복사 활동을 사용하여 WS1의 전용 SQL 풀에 있는 분할되지 않은 테이블에서 Azure Data Lake Storage Gen2 계정으로 데이터를 복사합니다. P2: 복사 활동을 사용하여 Azure Data Lake Storage Gen2 계정의 텍스트로 구분된 파일에서 데이터를 복사합니다. WS2의 전용 SQL 풀에 있는 파티션되지 않은 테이블에 병렬 처리와 성능을 최대화하려면 P1과 P2를 구성해야 합니다.
각 파이프라인의 경우 복사 활동에 대해 어떤 데이터세트 설정을 구성해야 합니까? 답변하려면 답변에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

ADF1에는 다음 파이프라인이 포함되어 있습니다.
P1: 복사 활동을 사용하여 WS1의 전용 SQL 풀에 있는 분할되지 않은 테이블에서 Azure Data Lake Storage Gen2 계정으로 데이터를 복사합니다. P2: 복사 활동을 사용하여 Azure Data Lake Storage Gen2 계정의 텍스트로 구분된 파일에서 데이터를 복사합니다. WS2의 전용 SQL 풀에 있는 파티션되지 않은 테이블에 병렬 처리와 성능을 최대화하려면 P1과 P2를 구성해야 합니다.
각 파이프라인의 경우 복사 활동에 대해 어떤 데이터세트 설정을 구성해야 합니까? 답변하려면 답변에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203 문제 102
Server1이라는 서버에 DW1이라는 Azure Synapse Analytics의 엔터프라이즈 데이터 웨어하우스가 있습니다.
각 DW1 배포에 대한 트랜잭션 로그 파일의 크기가 160GB보다 작은지 확인해야 합니다.
당신은 무엇을해야합니까?
각 DW1 배포에 대한 트랜잭션 로그 파일의 크기가 160GB보다 작은지 확인해야 합니다.
당신은 무엇을해야합니까?
DP-203 문제 103
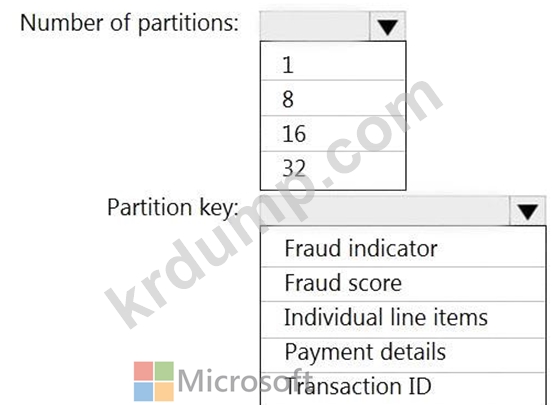
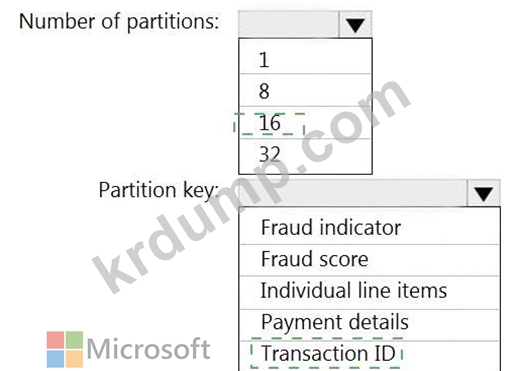
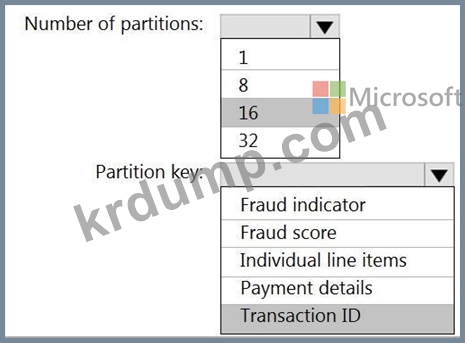
16개의 파티션이 있는 Retailhub라는 Azure 이벤트 허브가 있습니다. 거래는 Retailhub에 게시됩니다.
각 거래에는 거래 ID, 개별 항목 및 결제 세부정보가 포함됩니다. 트랜잭션 ID는 파티션 키로 사용됩니다.
소매점에서 잠재적으로 사기성 트랜잭션을 식별하기 위해 Azure Stream Analytics 작업을 디자인하고 있습니다. 작업은 Retailhub를 입력으로 사용합니다. 작업은 트랜잭션 ID, 개별 항목, 지불 세부 정보, 사기 점수 및 사기 표시기를 출력합니다.
Fraudhub라는 Azure 이벤트 허브로 출력을 보낼 계획입니다.
사기 탐지 솔루션이 확장성이 뛰어나고 가능한 한 빨리 거래를 처리하는지 확인해야 합니다.
Stream Analytics 작업의 출력을 어떻게 구성해야 합니까? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
각 거래에는 거래 ID, 개별 항목 및 결제 세부정보가 포함됩니다. 트랜잭션 ID는 파티션 키로 사용됩니다.
소매점에서 잠재적으로 사기성 트랜잭션을 식별하기 위해 Azure Stream Analytics 작업을 디자인하고 있습니다. 작업은 Retailhub를 입력으로 사용합니다. 작업은 트랜잭션 ID, 개별 항목, 지불 세부 정보, 사기 점수 및 사기 표시기를 출력합니다.
Fraudhub라는 Azure 이벤트 허브로 출력을 보낼 계획입니다.
사기 탐지 솔루션이 확장성이 뛰어나고 가능한 한 빨리 거래를 처리하는지 확인해야 합니다.
Stream Analytics 작업의 출력을 어떻게 구성해야 합니까? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
DP-203 문제 104
Azure Synapse Analytics 전용 SQL 풀에서 팩트 테이블에 대한 파티션 전략을 디자인하고 있습니다.
표에는 다음과 같은 사양이 있습니다.
* 20,000개의 제품에 대한 판매 데이터를 포함합니다.
* ProductlID라는 열에 해시 분포를 사용합니다.
* 2019년과 2020년에 대한 24억 개의 레코드를 포함합니다.
클러스터형 columnstore 인덱스의 최적 압축 및 성능을 제공하는 파티션 범위 수는 무엇입니까?
표에는 다음과 같은 사양이 있습니다.
* 20,000개의 제품에 대한 판매 데이터를 포함합니다.
* ProductlID라는 열에 해시 분포를 사용합니다.
* 2019년과 2020년에 대한 24억 개의 레코드를 포함합니다.
클러스터형 columnstore 인덱스의 최적 압축 및 성능을 제공하는 파티션 범위 수는 무엇입니까?
DP-203 문제 105
Azure Data Lake Storage Gen2를 사용하여 데이터 과학자 및 데이터 엔지니어가 Azure Databricks 대화형 노트북을 사용하여 쿼리할 데이터를 저장합니다. 사용자는 자신이 작업하는 프로젝트와 관련된 Data Lake Storage 폴더에만 액세스할 수 있습니다.
사용자에게 적절한 액세스 권한을 제공하려면 Databricks 및 Data Lake Storage에 사용할 인증 방법을 권장해야 합니다. 솔루션은 관리 노력과 개발 노력을 최소화해야 합니다.
각 Azure 서비스에 대해 어떤 인증 방법을 권장해야 하나요? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

사용자에게 적절한 액세스 권한을 제공하려면 Databricks 및 Data Lake Storage에 사용할 인증 방법을 권장해야 합니다. 솔루션은 관리 노력과 개발 노력을 최소화해야 합니다.
각 Azure 서비스에 대해 어떤 인증 방법을 권장해야 하나요? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
