DP-203 문제 51
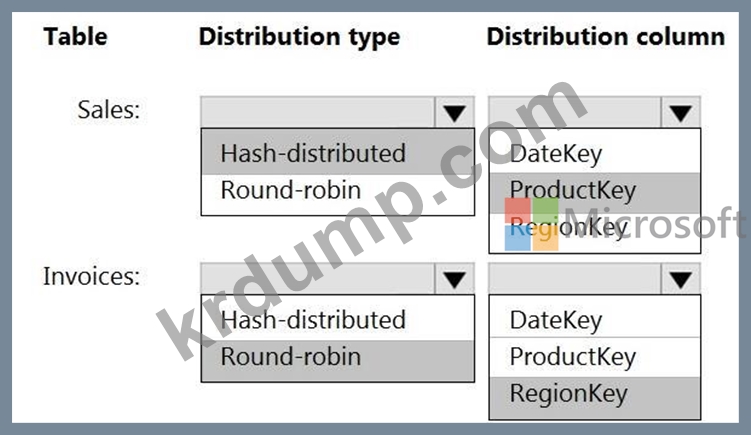
다음 팩트 테이블을 포함하는 온프레미스 데이터 웨어하우스가 있습니다. 두 테이블 모두 DateKey, ProductKey, RegionKey 열이 있습니다. 120개의 고유한 제품 키와 65개의 고유한 지역 키가 있습니다.

데이터 웨어하우스를 사용하는 쿼리는 완료하는 데 오랜 시간이 걸립니다.
Azure Synapse Analytics를 사용하도록 솔루션을 마이그레이션할 계획입니다. Azure 기반 솔루션이 쿼리 성능을 최적화하고 처리 왜곡을 최소화하는지 확인해야 합니다.
무엇을 추천해야 할까요? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

데이터 웨어하우스를 사용하는 쿼리는 완료하는 데 오랜 시간이 걸립니다.
Azure Synapse Analytics를 사용하도록 솔루션을 마이그레이션할 계획입니다. Azure 기반 솔루션이 쿼리 성능을 최적화하고 처리 왜곡을 최소화하는지 확인해야 합니다.
무엇을 추천해야 할까요? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203 문제 52
Azure Event Hub에서 스트리밍 데이터를 처리하고 데이터를 Azure Data Lake Storage로 출력하는 솔루션을 설계해야 합니다. 솔루션은 분석가가 스트리밍 데이터를 대화식으로 쿼리할 수 있도록 해야 합니다.
무엇을 사용해야합니까?
무엇을 사용해야합니까?
DP-203 문제 53
큰 팩트 테이블이 포함된 Azure Synapse Analytics 전용 SQL 풀이 있습니다. 테이블은 50개의 열과 50억 개의 행을 포함하며 힙입니다.
테이블에 대한 대부분의 쿼리는 약 1억 개의 행에서 값을 집계하고 두 개의 열만 반환합니다.
사실 테이블에 대한 쿼리가 매우 느리다는 것을 발견했습니다.
가장 빠른 쿼리 시간을 제공하려면 어떤 유형의 인덱스를 추가해야 합니까?
테이블에 대한 대부분의 쿼리는 약 1억 개의 행에서 값을 집계하고 두 개의 열만 반환합니다.
사실 테이블에 대한 쿼리가 매우 느리다는 것을 발견했습니다.
가장 빠른 쿼리 시간을 제공하려면 어떤 유형의 인덱스를 추가해야 합니까?
DP-203 문제 54
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만 다른 질문 세트에는 올바른 솔루션이 없을 수 있습니다.
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
계층 구조가 있는 Azure Databricks 작업 영역을 만들 계획입니다. 작업 공간에는 다음 세 가지 워크로드가 포함됩니다.
* Python 및 SQL을 사용할 데이터 엔지니어를 위한 워크로드.
* Python, Scala 및 SOL을 사용하는 노트북을 실행할 작업에 대한 워크로드.
* 데이터 과학자가 Scala 및 R에서 임시 분석을 수행하는 데 사용할 워크로드.
회사의 엔터프라이즈 아키텍처 팀은 Databricks 환경에 대해 다음 표준을 식별합니다.
* 데이터 엔지니어는 클러스터를 공유해야 합니다.
* 작업 클러스터는 데이터 과학자와 데이터 엔지니어가 클러스터에 배포할 패키지된 노트북을 제공하는 요청 프로세스를 사용하여 관리됩니다.
* 모든 데이터 과학자는 120분 동안 활동이 없으면 자동으로 종료되는 자체 클러스터를 할당해야 합니다. 현재 3명의 데이터 과학자가 있습니다.
워크로드에 대한 Databricks 클러스터를 만들어야 합니다.
솔루션: 각 데이터 과학자에 대한 표준 클러스터, 데이터 엔지니어에 대한 높은 동시성 클러스터, 작업에 대한 표준 클러스터를 생성합니다.
이것이 목표를 달성합니까?
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
계층 구조가 있는 Azure Databricks 작업 영역을 만들 계획입니다. 작업 공간에는 다음 세 가지 워크로드가 포함됩니다.
* Python 및 SQL을 사용할 데이터 엔지니어를 위한 워크로드.
* Python, Scala 및 SOL을 사용하는 노트북을 실행할 작업에 대한 워크로드.
* 데이터 과학자가 Scala 및 R에서 임시 분석을 수행하는 데 사용할 워크로드.
회사의 엔터프라이즈 아키텍처 팀은 Databricks 환경에 대해 다음 표준을 식별합니다.
* 데이터 엔지니어는 클러스터를 공유해야 합니다.
* 작업 클러스터는 데이터 과학자와 데이터 엔지니어가 클러스터에 배포할 패키지된 노트북을 제공하는 요청 프로세스를 사용하여 관리됩니다.
* 모든 데이터 과학자는 120분 동안 활동이 없으면 자동으로 종료되는 자체 클러스터를 할당해야 합니다. 현재 3명의 데이터 과학자가 있습니다.
워크로드에 대한 Databricks 클러스터를 만들어야 합니다.
솔루션: 각 데이터 과학자에 대한 표준 클러스터, 데이터 엔지니어에 대한 높은 동시성 클러스터, 작업에 대한 표준 클러스터를 생성합니다.
이것이 목표를 달성합니까?
DP-203 문제 55
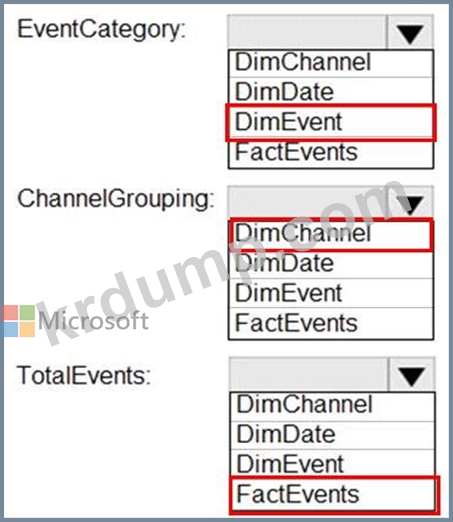
웹 사이트 분석 시스템에서 다운로드, 링크 클릭, 양식 제출 및 비디오 재생과 같은 사용자 상호 작용에 대한 데이터 추출을 받습니다.
데이터에는 다음 열이 포함됩니다.
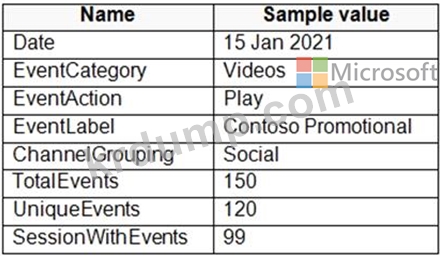
데이터의 분석 쿼리를 지원하려면 스타 스키마를 설계해야 합니다. 스타 스키마에는 날짜 차원을 포함하여 4개의 테이블이 포함됩니다.
각 열을 어떤 테이블에 추가해야 합니까? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
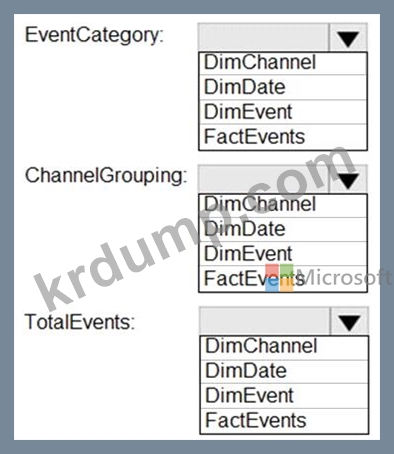
데이터에는 다음 열이 포함됩니다.
데이터의 분석 쿼리를 지원하려면 스타 스키마를 설계해야 합니다. 스타 스키마에는 날짜 차원을 포함하여 4개의 테이블이 포함됩니다.
각 열을 어떤 테이블에 추가해야 합니까? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.