
DP-203-KR 문제 1
WS1이라는 Azure Synapse Analytics 작업 영역이 있습니다.
다음 형식의 JSON 형식 파일을 포함하는 Azure Data Lake Storage Gen2 컨테이너가 있습니다.

파일을 읽으려면 WS1의 서버리스 SQL 풀을 사용해야 합니다.
Transact-SQL 문을 어떻게 완성해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
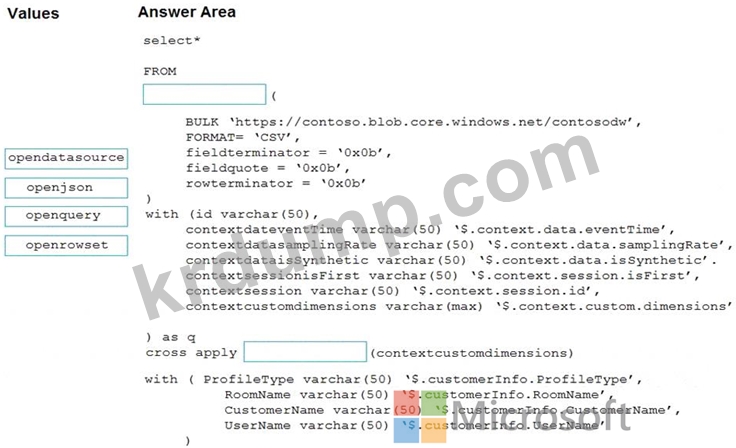
다음 형식의 JSON 형식 파일을 포함하는 Azure Data Lake Storage Gen2 컨테이너가 있습니다.
파일을 읽으려면 WS1의 서버리스 SQL 풀을 사용해야 합니다.
Transact-SQL 문을 어떻게 완성해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.


DP-203-KR 문제 2
Storage1 및 Storage2라는 두 개의 Azure Storage 계정이 있습니다. 각 계정에는 하나의 컨테이너가 있으며 계층적 네임스페이스가 활성화되어 있습니다. 시스템에는 Apache Parquet 형식으로 저장된 데이터가 포함된 파일이 있습니다.
Data Factory 복사 활동을 사용하여 Storage1에서 Storage2로 폴더 및 파일을 복사해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다.
어떠한 변환도 수행되지 않아야 합니다.
원래 폴더 구조를 유지해야 합니다.
복사 작업을 수행하는 데 필요한 시간을 최소화합니다.
복사 활동을 어떻게 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
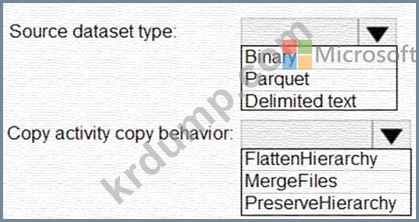
Data Factory 복사 활동을 사용하여 Storage1에서 Storage2로 폴더 및 파일을 복사해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다.
어떠한 변환도 수행되지 않아야 합니다.
원래 폴더 구조를 유지해야 합니다.
복사 작업을 수행하는 데 필요한 시간을 최소화합니다.
복사 활동을 어떻게 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.


DP-203-KR 문제 3
데이터 웨어하우스의 차원 테이블을 디자인하고 있습니다. 테이블은 시간이 지남에 따라 차원 특성 값을 추적하고 데이터가 변경될 때 새 행을 추가하여 데이터 기록을 보존합니다.
어떤 유형의 느린 변화 차원(SCD)을 사용해야 합니까?
어떤 유형의 느린 변화 차원(SCD)을 사용해야 합니까?
DP-203-KR 문제 4
영국 남부 지역의 Azure Synapse Analytics에 Azure Storage 계정과 데이터 웨어하우스가 있습니다.
Azure Data Factory를 사용하여 스토리지 계정에서 데이터 웨어하우스로 Blob 데이터를 복사해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다.
데이터가 항상 영국 남부 지역에 남아 있는지 확인하십시오.
관리 노력을 최소화합니다.
어떤 유형의 통합 런타임을 사용해야 하나요?
Azure Data Factory를 사용하여 스토리지 계정에서 데이터 웨어하우스로 Blob 데이터를 복사해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다.
데이터가 항상 영국 남부 지역에 남아 있는지 확인하십시오.
관리 노력을 최소화합니다.
어떤 유형의 통합 런타임을 사용해야 하나요?

DP-203-KR 문제 5
Azure Synapse Analytics 서버리스 SQ1 풀이 있습니다.
container1이라는 공용 컨테이너를 포함하는 aols1이라는 Azure Data Lake Storage 계정이 있습니다. 컨테이너 1 컨테이너에는 폴더 1이라는 폴더가 있습니다.
폴더 1에 있는 모든 CSV 파일의 상위 100개 행을 쿼리해야 합니다.
어떻게 shouk1 쿼리를 완료합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고 각 올바른 선택은 1점의 가치가 있습니다.

container1이라는 공용 컨테이너를 포함하는 aols1이라는 Azure Data Lake Storage 계정이 있습니다. 컨테이너 1 컨테이너에는 폴더 1이라는 폴더가 있습니다.
폴더 1에 있는 모든 CSV 파일의 상위 100개 행을 쿼리해야 합니다.
어떻게 shouk1 쿼리를 완료합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고 각 올바른 선택은 1점의 가치가 있습니다.

