
Databricks-Certified-Professional-Data-Scientist 문제 6
소매점에 대한 100,000명의 고객 행동을 분류하기 위해 k-평균 클러스터링을 사용했습니다. 가구 소득, 연령, 성별 및 연간 구매 금액을 측정값으로 사용하기로 결정합니다. 8개의 클러스터를 사용하도록 선택했으며 2개의 클러스터에는 3명의 고객만 할당되어 있습니다. 당신은 무엇을해야합니까?
Databricks-Certified-Professional-Data-Scientist 문제 7
지원 벡터 머신(SVM)은 다음을 위해 사용되는 지도 학습 방법 세트입니다.
Databricks-Certified-Professional-Data-Scientist 문제 8
1000개의 웹사이트에 대한 100개의 매개변수(예: 일일 조회수, 웹사이트 평균 시간, 고유 방문자 수, 재방문자 수 등)를 수집했습니다. 이제 웹사이트를 가장 잘 설명할 수 있는 가장 중요한 매개변수를 찾았습니다. 사용할 다음 기술 중
Databricks-Certified-Professional-Data-Scientist 문제 9
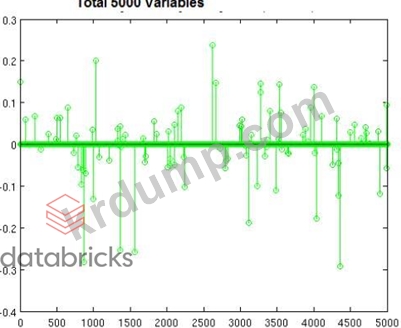
5000개의 변수(많은 행이 아니라 많은 열)가 있는 이미지에 표시된 것과 유사한 매우 높은 차원의 데이터 세트에서 분류기를 구축하고 있습니다. 고밀도 입력과 희소 입력을 모두 처리할 수 있습니다. 어떤 기술이 가장 적합하며 그 이유는 무엇입니까?
Databricks-Certified-Professional-Data-Scientist 문제 10
데이터 과학자는 온라인 잡지에 대한 기사 추천 기능을 구현해 달라는 요청을 받았습니다.
이 잡지는 쿠키나 읽기 기록과 같은 클라이언트 추적 기술을 사용하는 것을 원하지 않습니다. 따라서 현재 기사의 스타일과 주제만 추천할 수 있습니다. 잡지의 모든 기사는 분석에 적합한 형식으로 데이터베이스에 저장됩니다.
데이터 과학자는 어떤 방법을 먼저 시도해야 하나요?
이 잡지는 쿠키나 읽기 기록과 같은 클라이언트 추적 기술을 사용하는 것을 원하지 않습니다. 따라서 현재 기사의 스타일과 주제만 추천할 수 있습니다. 잡지의 모든 기사는 분석에 적합한 형식으로 데이터베이스에 저장됩니다.
데이터 과학자는 어떤 방법을 먼저 시도해야 하나요?