
DP-600-KR 문제 51
PoC(개념 증명)를 위해 임차인을 준비시킬 수 있는 솔루션을 추천해야 합니다.
Fabric 관리자 포털에서 수행해야 할 두 가지 작업은 무엇입니까? 각 정답은 해결책의 일부를 나타냅니다.
참고: 정답 하나당 1점입니다.
Fabric 관리자 포털에서 수행해야 할 두 가지 작업은 무엇입니까? 각 정답은 해결책의 일부를 나타냅니다.
참고: 정답 하나당 1점입니다.
정답: A,E
The PoC is planned to be completed using a Fabric trial capacity, which implies that users involved in the PoC should be able to try paid features. However, this should be limited to specific security groups involved in the PoC to prevent the entire organization from accessing the se features before the trial is proven successful (A). The ability for users to create Fabric items should also be enabled for specific security groups to ensure that only the relevant team members participating in the PoC can create items in the Fabric en vironment (E).
Topic 1, Litware. Inc. Case Study
Overview
Litware. Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment
litware has been using a Microsoft Power Bl tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Fabric En vironment
Litware has data that must be analyzed as shown in the following table.

The Product data contains a single table and the following columns.
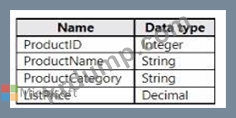
The customer satisfaction data contains the following tables:
* Survey
* Question
* Response
For each survey submitted, the following occurs:
* One row is added to the Survey table.
* One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Planned Changes
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Litware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity.
The following three workspaces will be created:
* AnalyticsPOC: Will contain the data store, semantic models, reports, pipelines, dataflows, and notebooks used to populate the data store
* DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate Onelake
* DataSciPOC: Will contain all the notebooks and reports created by the data scientists The following will be created in the AnalyticsPOC workspace:
* A data store (type to be decided)
* A custom semantic model
* A default semantic model
* Interactive reports
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers ' discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements
The data store must support the following:
* Read access by using T-SQL or Python
* Semi-structured and unstructured data
* Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model.
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model.
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SQL queries and in the default semantic model. The following logic must be used:
* List prices that are less than or equal to 50 are in the low pricing group.
* List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
* List pnces that are greater than 1,000 are in the high pricing group.
Security Requirements
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC. Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
* Fabric administrators will be the workspace administrators.
* The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
* The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
* The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook.
* The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power Bl reports by using the semantic models created by the analytics engineers.
* The date dimension must be available to all users of the data store.
* The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
* FabricAdmins: Fabric administrators
* AnalyticsTeam: All the members of the analytics team
* DataAnalysts: The data analysts on the analytics team
* DataScientists: The data scientists on the analytics team
* Data Engineers: The data engineers on the analytics team
* Analytics Engineers: The analytics engineers on the analytics team
Report Requirements
The data analysis must create a customer satisfaction report that meets the following requirements:
* Enables a user to select a product to filter customer survey responses to only those who have purchased that product
* Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected date
* Shows data as soon as the data is updated in the data store
* Ensures that the report and the semantic model only contain data from the current and previous year
* Ensures that the report respects any table-level security specified in the source data store
* Minimizes the execution time of report queries
Topic 1, Litware. Inc. Case Study
Overview
Litware. Inc. is a manufacturing company that has offices throughout North America. The analytics team at Litware contains data engineers, analytics engineers, data analysts, and data scientists.
Existing Environment
litware has been using a Microsoft Power Bl tenant for three years. Litware has NOT enabled any Fabric capacities and features.
Fabric En vironment
Litware has data that must be analyzed as shown in the following table.
The Product data contains a single table and the following columns.
The customer satisfaction data contains the following tables:
* Survey
* Question
* Response
For each survey submitted, the following occurs:
* One row is added to the Survey table.
* One row is added to the Response table for each question in the survey.
The Question table contains the text of each survey question. The third question in each survey response is an overall satisfaction score. Customers can submit a survey after each purchase.
User Problems
The analytics team has large volumes of data, some of which is semi-structured. The team wants to use Fabric to create a new data store.
Product data is often classified into three pricing groups: high, medium, and low. This logic is implemented in several databases and semantic models, but the logic does NOT always match across implementations.
Planned Changes
Litware plans to enable Fabric features in the existing tenant. The analytics team will create a new data store as a proof of concept (PoC). The remaining Litware users will only get access to the Fabric features once the PoC is complete. The PoC will be completed by using a Fabric trial capacity.
The following three workspaces will be created:
* AnalyticsPOC: Will contain the data store, semantic models, reports, pipelines, dataflows, and notebooks used to populate the data store
* DataEngPOC: Will contain all the pipelines, dataflows, and notebooks used to populate Onelake
* DataSciPOC: Will contain all the notebooks and reports created by the data scientists The following will be created in the AnalyticsPOC workspace:
* A data store (type to be decided)
* A custom semantic model
* A default semantic model
* Interactive reports
The data engineers will create data pipelines to load data to OneLake either hourly or daily depending on the data source. The analytics engineers will create processes to ingest transform, and load the data to the data store in the AnalyticsPOC workspace daily. Whenever possible, the data engineers will use low-code tools for data ingestion. The choice of which data cleansing and transformation tools to use will be at the data engineers ' discretion.
All the semantic models and reports in the Analytics POC workspace will use the data store as the sole data source.
Technical Requirements
The data store must support the following:
* Read access by using T-SQL or Python
* Semi-structured and unstructured data
* Row-level security (RLS) for users executing T-SQL queries
Files loaded by the data engineers to OneLake will be stored in the Parquet format and will meet Delta Lake specifications.
Data will be loaded without transformation in one area of the AnalyticsPOC data store. The data will then be cleansed, merged, and transformed into a dimensional model.
The data load process must ensure that the raw and cleansed data is updated completely before populating the dimensional model.
The dimensional model must contain a date dimension. There is no existing data source for the date dimension. The Litware fiscal year matches the calendar year. The date dimension must always contain dates from 2010 through the end of the current year.
The product pricing group logic must be maintained by the analytics engineers in a single location. The pricing group data must be made available in the data store for T-SQL queries and in the default semantic model. The following logic must be used:
* List prices that are less than or equal to 50 are in the low pricing group.
* List prices that are greater than 50 and less than or equal to 1,000 are in the medium pricing group.
* List pnces that are greater than 1,000 are in the high pricing group.
Security Requirements
Only Fabric administrators and the analytics team must be able to see the Fabric items created as part of the PoC. Litware identifies the following security requirements for the Fabric items in the AnalyticsPOC workspace:
* Fabric administrators will be the workspace administrators.
* The data engineers must be able to read from and write to the data store. No access must be granted to datasets or reports.
* The analytics engineers must be able to read from, write to, and create schemas in the data store. They also must be able to create and share semantic models with the data analysts and view and modify all reports in the workspace.
* The data scientists must be able to read from the data store, but not write to it. They will access the data by using a Spark notebook.
* The data analysts must have read access to only the dimensional model objects in the data store. They also must have access to create Power Bl reports by using the semantic models created by the analytics engineers.
* The date dimension must be available to all users of the data store.
* The principle of least privilege must be followed.
Both the default and custom semantic models must include only tables or views from the dimensional model in the data store. Litware already has the following Microsoft Entra security groups:
* FabricAdmins: Fabric administrators
* AnalyticsTeam: All the members of the analytics team
* DataAnalysts: The data analysts on the analytics team
* DataScientists: The data scientists on the analytics team
* Data Engineers: The data engineers on the analytics team
* Analytics Engineers: The analytics engineers on the analytics team
Report Requirements
The data analysis must create a customer satisfaction report that meets the following requirements:
* Enables a user to select a product to filter customer survey responses to only those who have purchased that product
* Displays the average overall satisfaction score of all the surveys submitted during the last 12 months up to a selected date
* Shows data as soon as the data is updated in the data store
* Ensures that the report and the semantic model only contain data from the current and previous year
* Ensures that the report respects any table-level security specified in the source data store
* Minimizes the execution time of report queries
DP-600-KR 문제 52
시맨틱 모델을 포함하는 Fabric 테넌트가 있습니다. 해당 모델은 Direct Lake 모드를 사용합니다.
DAX 쿼리 중 일부가 불필요한 열을 메모리에 로드하는 것으로 의심됩니다.
메모리에 로드되는 자주 사용되는 열을 식별해야 합니다.
목표를 달성하는 두 가지 방법은 무엇입니까? 각 정답은 완전한 해결책을 제시합니다.
참고: 정답 하나당 1점입니다.
DAX 쿼리 중 일부가 불필요한 열을 메모리에 로드하는 것으로 의심됩니다.
메모리에 로드되는 자주 사용되는 열을 식별해야 합니다.
목표를 달성하는 두 가지 방법은 무엇입니까? 각 정답은 완전한 해결책을 제시합니다.
참고: 정답 하나당 1점입니다.
정답: A,C
The Vertipaq Analyzer tool (B) and querying the $system.
discovered_STORAGE_TABLE_COLUMNS_IN_SEGMENTS dynamic management view (DMV) (C) can help identify which columns are frequently loaded into memory. Both methods provide insights into the storage and retrieval aspects of the semantic model. References = The Power BI documentation on Vertipaq Analyzer and DMV queries offers detailed guidance on how to use these tools for performance analysis.
discovered_STORAGE_TABLE_COLUMNS_IN_SEGMENTS dynamic management view (DMV) (C) can help identify which columns are frequently loaded into memory. Both methods provide insights into the storage and retrieval aspects of the semantic model. References = The Power BI documentation on Vertipaq Analyzer and DMV queries offers detailed guidance on how to use these tools for performance analysis.
DP-600-KR 문제 53
귀하는 창고를 포함하는 Fabric 테넌트를 보유하고 있습니다.
하루에 여러 번, 모든 데이터 웨어하우스 쿼리의 성능이 저하됩니다. Fabric이 데이터 웨어하우스에서 사용하는 컴퓨팅 리소스를 제한하고 있는 것으로 의심됩니다.
스로틀링이 발생하는지 확인하려면 무엇을 사용해야 할까요?
하루에 여러 번, 모든 데이터 웨어하우스 쿼리의 성능이 저하됩니다. Fabric이 데이터 웨어하우스에서 사용하는 컴퓨팅 리소스를 제한하고 있는 것으로 의심됩니다.
스로틀링이 발생하는지 확인하려면 무엇을 사용해야 할까요?
정답: D
To identify whether throttling is occurring, you should use the Monitoring hub (B). This provides a centralized place where you can monitor and manage the health, performance, and reliability of your data estate, and see if the compute resources are being throttled. References = The use o f the Monitoring hub for performance management and troubleshooting is detailed in the Azure Synapse Analytics documentation.
DP-600-KR 문제 54
고객 만족도 보고서에 대한 의미론적 모델을 설계해야 합니다.
어떤 데이터 소스 인증 방법과 모드를 사용해야 합니까? 답변하려면 답변 영역에서 적절한 옵션을 선택하십시오.
참고: 정답 하나당 1점입니다.
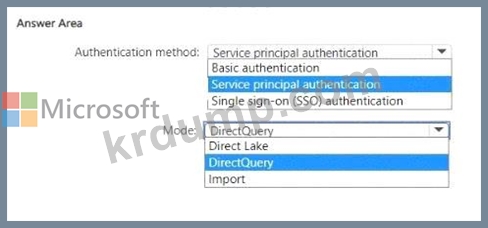
어떤 데이터 소스 인증 방법과 모드를 사용해야 합니까? 답변하려면 답변 영역에서 적절한 옵션을 선택하십시오.
참고: 정답 하나당 1점입니다.
정답:
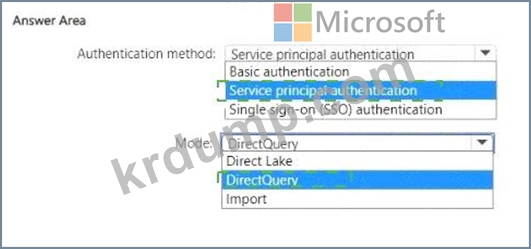
Explanation:

For the semantic model design required for the customer satisfaction report, the choices for data source authentication method and mode should be made b ased on security and performance considerations as per the case study provided.
Authentication method: The data should be accessed securely, and given that row-level security (RLS) is required for users executing T-SQL queries, you should use an authentica tion method that supports RLS.
Service principal authentication is suitable for automated and secure access to the data, especially when the access needs to be controlled programmatically and is not tied to a specific user ' s credentials.
Mode: The report n eeds to show data as soon as it is updated in the data store, and it should only contain data from the current and previous year. DirectQuery mode allows for real-time reporting without importing data into the model, thus meeting the need for up-to-date da ta. It also allows for RLS to be implemented and enforced at the data source level, providing the necessary security measures.
Based on these considerations, the selections should be:
Authentication method: Service principal authentication
Mode: DirectQuery
Topic 2, Contoso, ltd.
Overview
Contoso, ltd. is a US-based health supplements company, Contoso has two divisions named Sales and Research. The Sales division contains two departments named Online Sales and Retail Sales. The Research division assigns internally developed product lines to individual teams of researchers and analysts.
Identity Environment
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroupi and ReseachReviewefsGfoup2.
Data Environment
Contoso has the following data environment
* The Sales division uses a Microsoft Power B1 Premium capacity.
* The semantic model of the Online Sales department includes a fact table named Orders that uses import mode. In the system of origin, the OrderlD value represents the sequence in which orders are created.
* The Research department uses an on-premises. third-party data warehousing product.
* Fabric is enabled for contoso.com.
* An Azure Data Lake Storage Gen2 storage account named storage1 contains Research division data for a product line named Producthne1. The data is in the delta format.
* A Data Lake Storage Gen2 storage account named storage2 contains Research division data for a product line named Productline2. The data is in the CSV format.
Planned Changes
Contoso plans to make the following changes:
* Enable support for Fabric in the Power Bl Premium capacity used by the Sales division.
* Make all the data for the Sales division and the Research division available in Fabric.
* For the Research division, create two Fabric workspaces named Producttmelws and Productline2ws.
* in Productlinelws. create a lakehouse named LakehouseV
* In Lakehouse1. create a shortcut to storage1 named ResearchProduct.
Data Analytics Requirements
Contoso identifies the following data analytics requirements:
* All the workspaces for the Sales division and the Research division must support all Fabric experiences.
* The Research division workspaces must use a dedicated, on-demand capacity that has per-minute billing.
* The Research division workspaces must be grouped together logically to support OneLake data hub filtering based on the department name.
* For the Research division workspaces, the members of ResearchRevtewersGroupl must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
* For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
* All the semantic models and reports for the Research division must use version control that supports branching Data Preparation Requirements Contoso identifies the following data preparation requirements:
* The Research division data for Producthne2 must be retrieved from Lakehouset by using Fabric notebooks.
* All the Research division data in the lakehouses must be presented as managed tables in Lakehouse explorer.
Semantic Model Requirements
Contoso identifies the following requirements for implementing and managing semantic models;
* The number of rows added to the Orders table during refreshes must be minimized.
* The semantic models in the Research division workspaces must use Direct Lake mode.
General Requirements
Contoso identifies the following high-level requirements that must be considered for all solutions:
* Follow the principle of least privilege when applicable
* Minimize implementation and maintenance effort when possible.
DP-600-KR 문제 55
다음 그림에 나와 있는 소스 데이터 모델이 있습니다.

테이블의 기본 키는 각 키에 관련된 열 옆에 열쇠 모양 기호로 표시됩니다.
날짜, 제품, 고객별 주문 품목 분석이 가능한 차원 데이터 모델을 만들어야 합니다.
해결책에 무엇을 포함해야 할까요? 답변하려면 답변란에서 적절한 옵션을 선택하세요.
참고: 정답 하나당 1점입니다.

테이블의 기본 키는 각 키에 관련된 열 옆에 열쇠 모양 기호로 표시됩니다.
날짜, 제품, 고객별 주문 품목 분석이 가능한 차원 데이터 모델을 만들어야 합니다.
해결책에 무엇을 포함해야 할까요? 답변하려면 답변란에서 적절한 옵션을 선택하세요.
참고: 정답 하나당 1점입니다.
정답:

Explanation:

The relationship between OrderItem and Product must be based on: Both the CompanyID and the ProductID columns The Company entity must be: Denormalized into the Customer and Product entities In a dimensional model, the relationships are typically based on foreign key constraints between the fact table (OrderItem) and dimension tables (Product, Customer, Date). Since CompanyID is present in both the OrderItem and Product tables, it acts as a foreign key in the relationsh ip. Similarly, ProductID is a foreign key that relates these two tables. To enable analysis by date, product, and customer, the Company entity would need to be denormalized into the Customer and Product entities to ensure that the relevant company informat ion is available within those dimensions for querying and reporting purposes.
References =
Dimensional modeling
Star schema design
- 최근 업로드
- 108Microsoft.AZ-500-KR.v2026-06-04.q213
- 110Microsoft.DP-600-KR.v2026-06-04.q98
- 105Microsoft.AZ-204-KR.v2026-06-04.q237
- 136Microsoft.PL-600-KR.v2026-06-04.q112
- 190Microsoft.SC-300-KR.v2026-06-03.q151
- 151Microsoft.DP-600-KR.v2026-06-03.q70
- 866PMI.PMP-KR.v2026-06-01.q1069
- 227Microsoft.MS-102-KR.v2026-06-01.q252
- 207Amazon.DOP-C02-KR.v2026-06-01.q207
- 159Microsoft.AZ-104-KR.v2026-06-01.q197
[×]
PDF 파일 다운로드
메일 주소를 입력하시고 다운로드 하세요. Microsoft.DP-600-KR.v2026-06-03.q70 모의시험 시험자료를 다운 받으세요.