
DP-100 문제 191
Azure Machine Learning Studio를 사용하여 데이터 세트를 분석하고 있습니다.
p 값과 각 특성 열에 대한 고유 값 수가 포함된 통계 요약을 생성해야 합니다.
어떤 두 가지 모듈을 사용할 수 있습니까? 각 정답은 완전한 솔루션을 제공합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
p 값과 각 특성 열에 대한 고유 값 수가 포함된 통계 요약을 생성해야 합니다.
어떤 두 가지 모듈을 사용할 수 있습니까? 각 정답은 완전한 솔루션을 제공합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
DP-100 문제 192
x.1 x2 및 x3 기능용 scikit-learn Python 라이브러리를 사용하여 기능 확장을 수행하고 있습니다.
원본 및 크기 조정된 데이터는 다음 이미지에 표시됩니다.

드롭다운 메뉴를 사용하여 그래픽에 표시된 정보를 기반으로 각 질문에 대한 답변을 선택합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

원본 및 크기 조정된 데이터는 다음 이미지에 표시됩니다.
드롭다운 메뉴를 사용하여 그래픽에 표시된 정보를 기반으로 각 질문에 대한 답변을 선택합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.



DP-100 문제 193
Azure Machine Learning Studio에서 실험을 만듭니다. 10,000개의 행이 포함된 훈련 데이터 세트를 추가합니다. 처음 9,000개의 행은 클래스 0(90%)을 나타냅니다.
나머지 1,000개 행은 클래스 1(10%)을 나타냅니다.
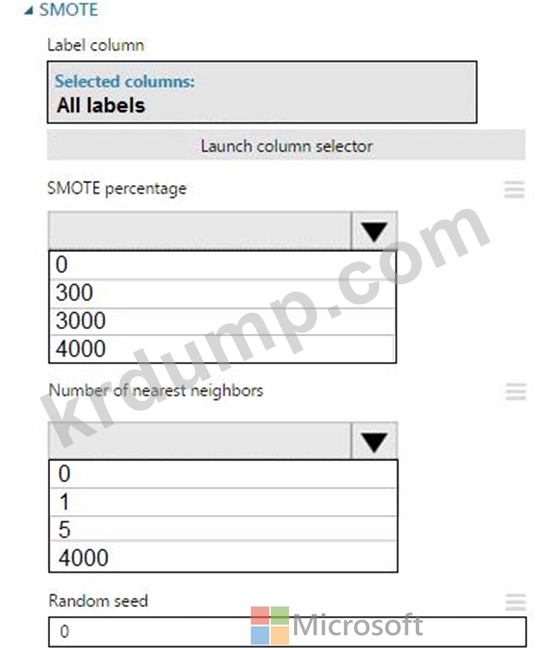
훈련 세트는 두 클래스 간의 불균형입니다. 5개의 데이터 행을 사용하여 클래스 1에 대한 학습 예제의 수를 4,000개로 늘려야 합니다. 실험에 SMOTE(Synthetic Minority Oversampling Technique) 모듈을 추가합니다.
모듈을 구성해야 합니다.
어떤 값을 사용해야 합니까? 응답하려면 응답 영역의 대화 상자에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
나머지 1,000개 행은 클래스 1(10%)을 나타냅니다.
훈련 세트는 두 클래스 간의 불균형입니다. 5개의 데이터 행을 사용하여 클래스 1에 대한 학습 예제의 수를 4,000개로 늘려야 합니다. 실험에 SMOTE(Synthetic Minority Oversampling Technique) 모듈을 추가합니다.
모듈을 구성해야 합니다.
어떤 값을 사용해야 합니까? 응답하려면 응답 영역의 대화 상자에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-100 문제 194
완료된 이진 분류 기계 학습 모델을 평가하고 있습니다.
평가 지표로 정밀도를 사용해야 합니다.
어떤 시각화를 사용해야 합니까?
평가 지표로 정밀도를 사용해야 합니다.
어떤 시각화를 사용해야 합니까?



DP-100 문제 195
x.1 x2 및 x3 기능용 scikit-learn Python 라이브러리를 사용하여 기능 확장을 수행하고 있습니다.
원본 및 크기 조정된 데이터는 다음 이미지에 표시됩니다.

드롭다운 메뉴를 사용하여 그래픽에 표시된 정보를 기반으로 각 질문에 대한 답변을 선택합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

원본 및 크기 조정된 데이터는 다음 이미지에 표시됩니다.
드롭다운 메뉴를 사용하여 그래픽에 표시된 정보를 기반으로 각 질문에 대한 답변을 선택합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

