
Databricks-Certified-Professional-Data-Engineer 문제 66
데이터 분석가 팀은 주문 및 보충을 기반으로 재고가 없는 항목을 식별하는 쿼리를 조합했지만 최종 출력을 위해 모두 함께 실행했을 때 팀은 정말 오랜 시간이 걸린다는 것을 알았습니다. 느리게 실행되고 성능을 개선하기 위한 단계를 식별하고 그것을 보았을 때 모든 코드 쿼리가 순차적으로 실행되고 SQL 끝점 클러스터를 사용하고 있음을 알았습니다. 다음 중 문제를 해결하기 위해 취할 수 있는 조치는 무엇입니까?
다음은 예제 쿼리입니다.
1.--- 주문 요약 받기
2. 테이블 orders_summary 생성 또는 교체
3.as
4.product_id, sum(order_count) order_count 선택
5.에서
6. (
7. orders_instore에서 product_id, order_count 선택
8. 모두 합체
9. orders_online에서 product_id, order_count 선택
10. )
11. product_id별 그룹
12.-- 공급 요약 가져오기
13.생성 또는 교체 테이블 supply_summary
14.as
15.product_id 선택, sum(supply_count) supply_count
16. 공급에서
17. product_id별 그룹
18.
19.-- 주문 요약 및 공급 요약을 기반으로 손에 넣기
20.
21.stock_cte 포함
22.as(
23. nvl(s.product_id,o.product_id)을 product_id로 선택하고,
24. nvl(supply_count,0) - nvl(order_count,0) as on_hand
25. from supply_summary s
26. 전체 외부 조인 주문_요약 o
27. s.product_id = o.product_id에서
28.)
29. 선택 *
30.부터
31.stock_cte
32. 여기서 on_hand = 0
다음은 예제 쿼리입니다.
1.--- 주문 요약 받기
2. 테이블 orders_summary 생성 또는 교체
3.as
4.product_id, sum(order_count) order_count 선택
5.에서
6. (
7. orders_instore에서 product_id, order_count 선택
8. 모두 합체
9. orders_online에서 product_id, order_count 선택
10. )
11. product_id별 그룹
12.-- 공급 요약 가져오기
13.생성 또는 교체 테이블 supply_summary
14.as
15.product_id 선택, sum(supply_count) supply_count
16. 공급에서
17. product_id별 그룹
18.
19.-- 주문 요약 및 공급 요약을 기반으로 손에 넣기
20.
21.stock_cte 포함
22.as(
23. nvl(s.product_id,o.product_id)을 product_id로 선택하고,
24. nvl(supply_count,0) - nvl(order_count,0) as on_hand
25. from supply_summary s
26. 전체 외부 조인 주문_요약 o
27. s.product_id = o.product_id에서
28.)
29. 선택 *
30.부터
31.stock_cte
32. 여기서 on_hand = 0
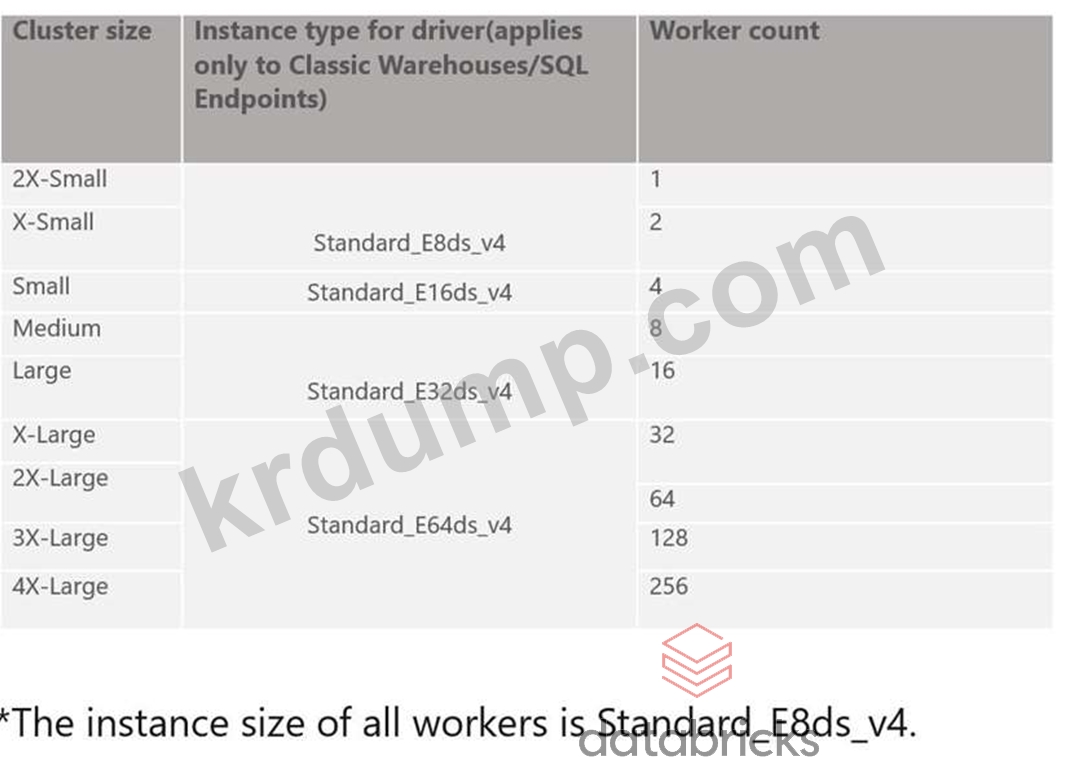
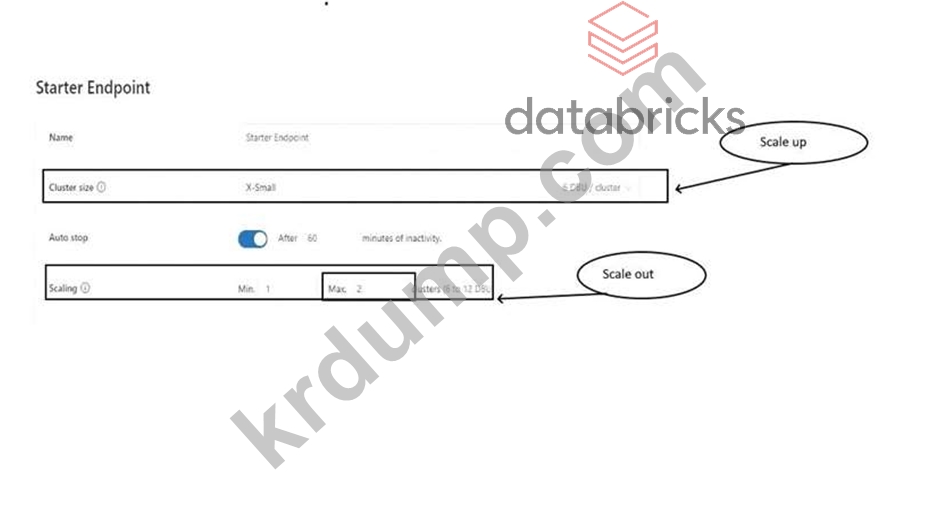
Databricks-Certified-Professional-Data-Engineer 문제 67
DLT 파이프라인을 구축할 때 라이브 테이블을 생성하는 두 가지 옵션이 있습니다. CREATE STREAMING LIVE TABLE과 CREATE LIVE TABLE의 주요 차이점은 무엇입니까?
Databricks-Certified-Professional-Data-Engineer 문제 68
레이크하우스와 데이터웨어하우스 중에서 선택할 때 올바른 설명은 무엇입니까?
Databricks-Certified-Professional-Data-Engineer 문제 69
데이터 엔지니어링 팀은 모두 동일한 조건을 충족하는 행을 추출하기 위해 델타 테이블을 쿼리해야 합니다.
그러나 팀은 쿼리가 느리게 실행되고 있음을 확인했습니다. 팀은 이미 크기를 조정했습니다.
데이터 파일. 조사 결과, 팀은 조건을 충족하는 행이 드물게 위치한다는 결론을 내렸습니다.
각 데이터 파일 전체에서.
시나리오에 따라 다음 최적화 기술 중 쿼리 속도를 높일 수 있는 것은 무엇입니까?
그러나 팀은 쿼리가 느리게 실행되고 있음을 확인했습니다. 팀은 이미 크기를 조정했습니다.
데이터 파일. 조사 결과, 팀은 조건을 충족하는 행이 드물게 위치한다는 결론을 내렸습니다.
각 데이터 파일 전체에서.
시나리오에 따라 다음 최적화 기술 중 쿼리 속도를 높일 수 있는 것은 무엇입니까?
Databricks-Certified-Professional-Data-Engineer 문제 70
VACCUM 및 OPTIMIZE 명령을 사용하여 DELTA 레이크를 관리하는 방법은 무엇입니까?