
DP-203 문제 71
고객용 JSON 파일이 포함된 Azure Data Lake Storage Gen2 계정이 있습니다. 파일에는 FirstName 및 LastName이라는 두 가지 특성이 포함되어 있습니다.
Azure Databricks를 사용하여 JSON 파일에서 Azure Synapse Analytics 테이블로 데이터를 복사해야 합니다. FirstName 및 LastName 값을 연결하는 새 열을 만들어야 합니다.
다음 구성 요소를 생성합니다.
Azure Synapse의 대상 테이블
Azure Blob 스토리지 컨테이너
서비스 주체
Databricks 노트북에서 다음에 순서대로 수행해야 하는 5가지 작업은 무엇인가요? 응답하려면 작업 목록에서 해당 작업을 응답 영역으로 이동하고 올바른 순서로 정렬하십시오.

Azure Databricks를 사용하여 JSON 파일에서 Azure Synapse Analytics 테이블로 데이터를 복사해야 합니다. FirstName 및 LastName 값을 연결하는 새 열을 만들어야 합니다.
다음 구성 요소를 생성합니다.
Azure Synapse의 대상 테이블
Azure Blob 스토리지 컨테이너
서비스 주체
Databricks 노트북에서 다음에 순서대로 수행해야 하는 5가지 작업은 무엇인가요? 응답하려면 작업 목록에서 해당 작업을 응답 영역으로 이동하고 올바른 순서로 정렬하십시오.

DP-203 문제 72
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 하나 이상의 올바른 솔루션이 있을 수 있지만 다른 질문 세트에는 올바른 솔루션이 없을 수 있습니다.
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
계층 구조가 있는 Azure Databricks 작업 영역을 만들 계획입니다. 작업 영역에는 다음 세 가지 워크로드가 포함됩니다.
Python 및 SQL을 사용할 데이터 엔지니어를 위한 워크로드입니다.
Python, Scala 및 SOL을 사용하는 노트북을 실행할 작업에 대한 워크로드입니다.
데이터 과학자가 Scala 및 R에서 임시 분석을 수행하는 데 사용할 워크로드입니다.
회사의 엔터프라이즈 아키텍처 팀은 Databricks 환경에 대해 다음 표준을 식별합니다.
데이터 엔지니어는 클러스터를 공유해야 합니다.
작업 클러스터는 데이터 과학자와 데이터 엔지니어가 클러스터에 배포할 패키지 노트북을 제공하는 요청 프로세스를 사용하여 관리됩니다.
모든 데이터 과학자에게는 120분 동안 활동이 없으면 자동으로 종료되는 자체 클러스터가 할당되어야 합니다. 현재 세 명의 데이터 과학자가 있습니다.
워크로드에 대한 Databricks 클러스터를 만들어야 합니다.
솔루션: 각 데이터 과학자를 위한 표준 클러스터, 데이터 엔지니어를 위한 표준 클러스터 및 작업을 위한 높은 동시성 클러스터를 만듭니다.
이것이 목표를 달성합니까?
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
계층 구조가 있는 Azure Databricks 작업 영역을 만들 계획입니다. 작업 영역에는 다음 세 가지 워크로드가 포함됩니다.
Python 및 SQL을 사용할 데이터 엔지니어를 위한 워크로드입니다.
Python, Scala 및 SOL을 사용하는 노트북을 실행할 작업에 대한 워크로드입니다.
데이터 과학자가 Scala 및 R에서 임시 분석을 수행하는 데 사용할 워크로드입니다.
회사의 엔터프라이즈 아키텍처 팀은 Databricks 환경에 대해 다음 표준을 식별합니다.
데이터 엔지니어는 클러스터를 공유해야 합니다.
작업 클러스터는 데이터 과학자와 데이터 엔지니어가 클러스터에 배포할 패키지 노트북을 제공하는 요청 프로세스를 사용하여 관리됩니다.
모든 데이터 과학자에게는 120분 동안 활동이 없으면 자동으로 종료되는 자체 클러스터가 할당되어야 합니다. 현재 세 명의 데이터 과학자가 있습니다.
워크로드에 대한 Databricks 클러스터를 만들어야 합니다.
솔루션: 각 데이터 과학자를 위한 표준 클러스터, 데이터 엔지니어를 위한 표준 클러스터 및 작업을 위한 높은 동시성 클러스터를 만듭니다.
이것이 목표를 달성합니까?
DP-203 문제 73
회사에서 PaaS(Platform-as-a-Service)를 사용하여 새로운 데이터 파이프라인 프로세스를 만들 계획입니다. 프로세스는 다음 요구 사항을 충족해야 합니다.
입수:
여러 데이터 소스에 액세스합니다.
워크플로를 오케스트레이션하는 기능을 제공합니다.
SQL Server Integration Services 패키지를 실행할 수 있는 기능을 제공합니다.
가게:
빅 데이터 워크로드에 맞게 스토리지를 최적화합니다.
저장된 데이터의 암호화를 제공합니다.
크기 제한 없이 작동합니다.
준비 및 교육:
탐색 및 시각화를 위한 완전 관리형 대화형 작업 공간을 제공합니다.
R, SQL, Python, Scala 및 Java로 프로그래밍할 수 있는 기능을 제공합니다.
Azure Active Directory를 사용하여 원활한 사용자 인증을 제공합니다.
모델 및 서비스:
네이티브 컬럼 스토리지를 구현합니다.
SQL 언어 지원
구조화된 스트리밍을 지원합니다.
데이터 통합 파이프라인을 구축해야 합니다.
어떤 기술을 사용해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
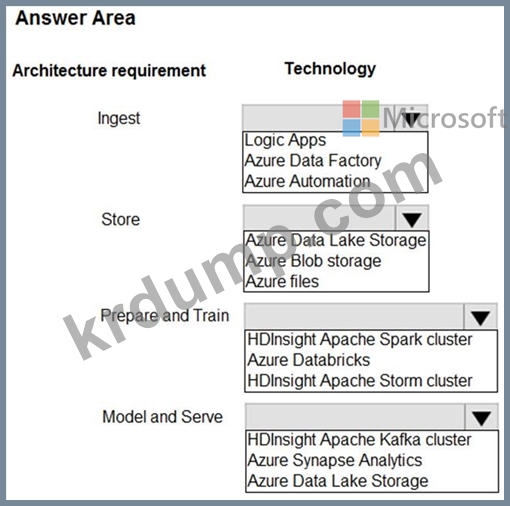
입수:
여러 데이터 소스에 액세스합니다.
워크플로를 오케스트레이션하는 기능을 제공합니다.
SQL Server Integration Services 패키지를 실행할 수 있는 기능을 제공합니다.
가게:
빅 데이터 워크로드에 맞게 스토리지를 최적화합니다.
저장된 데이터의 암호화를 제공합니다.
크기 제한 없이 작동합니다.
준비 및 교육:
탐색 및 시각화를 위한 완전 관리형 대화형 작업 공간을 제공합니다.
R, SQL, Python, Scala 및 Java로 프로그래밍할 수 있는 기능을 제공합니다.
Azure Active Directory를 사용하여 원활한 사용자 인증을 제공합니다.
모델 및 서비스:
네이티브 컬럼 스토리지를 구현합니다.
SQL 언어 지원
구조화된 스트리밍을 지원합니다.
데이터 통합 파이프라인을 구축해야 합니다.
어떤 기술을 사용해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203 문제 74
Database1이라는 Azure SQL 데이터베이스와 HubA 및 HubB라는 두 개의 Azure 이벤트 허브가 있습니다. 각 소스에서 소비되는 데이터는 다음 표와 같습니다.

운전자별 마일당 평균 요금을 계산하려면 Azure Stream Analytics를 구현해야 합니다.
각 소스에 대한 Stream Analytics 입력을 어떻게 구성해야 합니까? 대답하려면 대답에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

운전자별 마일당 평균 요금을 계산하려면 Azure Stream Analytics를 구현해야 합니다.
각 소스에 대한 Stream Analytics 입력을 어떻게 구성해야 합니까? 대답하려면 대답에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203 문제 75
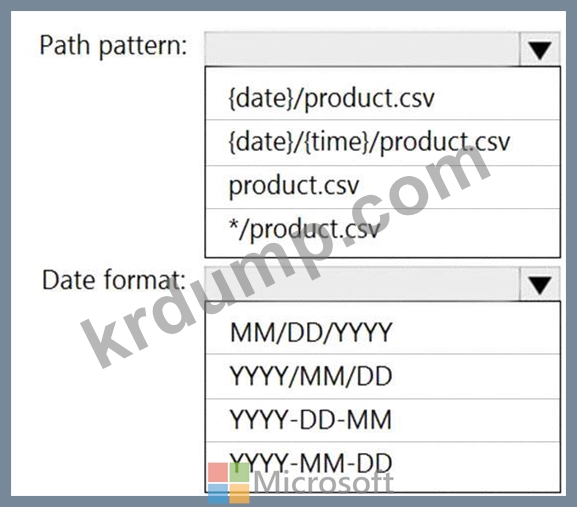
제품 카탈로그 파일에서 참조 데이터를 쿼리하는 Azure Stream Analytics 작업을 빌드하고 있습니다. 파일은 매일 업데이트됩니다.
파일에 대한 참조 데이터 입력 세부사항은 입력 전시회에 표시됩니다. (입력 탭을 클릭합니다.)

저장소 계정 컨테이너 보기는 Refdata 전시회에 표시됩니다. (Refdata 탭을 클릭합니다.)

새 참조 데이터를 선택하도록 Stream Analytics 작업을 구성해야 합니다.
무엇을 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
파일에 대한 참조 데이터 입력 세부사항은 입력 전시회에 표시됩니다. (입력 탭을 클릭합니다.)
저장소 계정 컨테이너 보기는 Refdata 전시회에 표시됩니다. (Refdata 탭을 클릭합니다.)
새 참조 데이터를 선택하도록 Stream Analytics 작업을 구성해야 합니다.
무엇을 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

