
DP-203 문제 46
Azure Data Factory를 사용하여 Azure Synapse Analytics 서버리스 SQL 풀에서 쿼리할 데이터를 준비합니다.
파일은 초기에 10개의 작은 JSON 파일로 Azure Data Lake Storage Gen2 계정에 수집됩니다. 각 파일에는 동일한 데이터 속성과 회사 자회사의 데이터가 포함되어 있습니다.
파일을 다른 폴더로 이동하고 다음 요구 사항을 충족하도록 데이터를 변환해야 합니다.
가능한 가장 빠른 쿼리 시간을 제공합니다.
기본 파일에서 스키마를 자동으로 유추합니다.
Data Factory 복사 작업을 어떻게 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
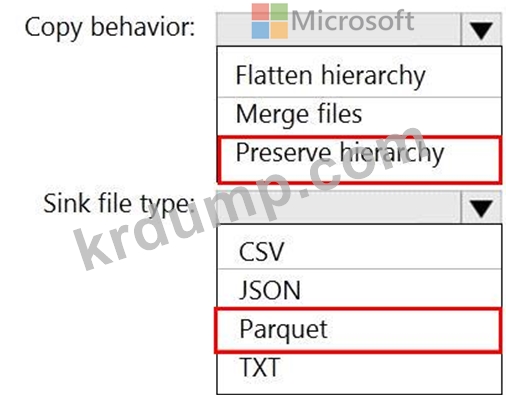
파일은 초기에 10개의 작은 JSON 파일로 Azure Data Lake Storage Gen2 계정에 수집됩니다. 각 파일에는 동일한 데이터 속성과 회사 자회사의 데이터가 포함되어 있습니다.
파일을 다른 폴더로 이동하고 다음 요구 사항을 충족하도록 데이터를 변환해야 합니다.
가능한 가장 빠른 쿼리 시간을 제공합니다.
기본 파일에서 스키마를 자동으로 유추합니다.
Data Factory 복사 작업을 어떻게 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
DP-203 문제 47
Azure Event Hub에서 스트리밍 데이터를 처리하고 데이터를 Azure Data Lake Storage로 출력하는 솔루션을 설계해야 합니다. 솔루션은 분석가가 스트리밍 데이터를 대화형으로 쿼리할 수 있도록 보장해야 합니다.
무엇을 사용해야 합니까?
무엇을 사용해야 합니까?
DP-203 문제 48
Df1이라는 Azure Data Factory 버전 2(V2) 리소스가 있습니다. Df1에는 연결된 서비스가 포함되어 있습니다.
key1이라는 암호화 키를 포함하는 vault1이라는 Azure Key Vault가 있습니다.
key1을 사용하여 Df1을 암호화해야 합니다.
먼저 무엇을 해야 합니까?
key1이라는 암호화 키를 포함하는 vault1이라는 Azure Key Vault가 있습니다.
key1을 사용하여 Df1을 암호화해야 합니다.
먼저 무엇을 해야 합니까?
DP-203 문제 49
준비 영역이 포함된 Azure Data Lake Storage 계정이 있습니다.
준비 영역에서 증분 데이터를 수집하고 R 스크립트를 실행하여 데이터를 변환한 다음 변환된 데이터를 Azure Synapse Analytics의 데이터 웨어하우스에 삽입하는 일일 프로세스를 설계해야 합니다.
해결 방법: Azure Data Factory 일정 트리거를 사용하여 매핑 데이터 흐름을 실행하는 파이프라인을 실행한 다음 데이터 웨어하우스에 데이터 정보를 삽입합니다.
이것이 목표를 달성합니까?
준비 영역에서 증분 데이터를 수집하고 R 스크립트를 실행하여 데이터를 변환한 다음 변환된 데이터를 Azure Synapse Analytics의 데이터 웨어하우스에 삽입하는 일일 프로세스를 설계해야 합니다.
해결 방법: Azure Data Factory 일정 트리거를 사용하여 매핑 데이터 흐름을 실행하는 파이프라인을 실행한 다음 데이터 웨어하우스에 데이터 정보를 삽입합니다.
이것이 목표를 달성합니까?
DP-203 문제 50
온-프레미스 데이터 원본과 Azure Synapse Analytics를 통합해야 합니다. 솔루션은 데이터 통합 요구 사항을 충족해야 합니다.
어떤 유형의 통합 런타임을 사용해야 합니까?
어떤 유형의 통합 런타임을 사용해야 합니까?