
DP-203 문제 87
Pipeline1 및 Pipeline2라는 두 개의 파이프라인이 포함된 Azure Data Factory 인스턴스가 있습니다.
Pipeline1에는 다음 전시에 표시된 활동이 있습니다.

Pipeline2에는 다음 전시회에 표시된 활동이 있습니다.

Pipeline2를 실행하고 Pipeline1의 저장 프로시저1이 실패합니다.
파이프라인 실행의 상태는 무엇입니까?
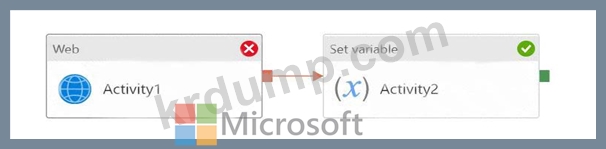
Pipeline1에는 다음 전시에 표시된 활동이 있습니다.
Pipeline2에는 다음 전시회에 표시된 활동이 있습니다.
Pipeline2를 실행하고 Pipeline1의 저장 프로시저1이 실패합니다.
파이프라인 실행의 상태는 무엇입니까?
DP-203 문제 88
Azure Synapse에 SQL 풀이 있습니다.
Azure Blob Storage에서 준비 테이블로 데이터를 로드할 계획입니다. 매일 약 100만 행의 데이터가 로드됩니다. 매일 로드하기 전에 테이블이 잘립니다.
스테이징 테이블을 생성해야 합니다. 솔루션은 데이터를 준비 테이블에 로드하는 데 걸리는 시간을 최소화해야 합니다.
테이블을 어떻게 구성해야 합니까? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
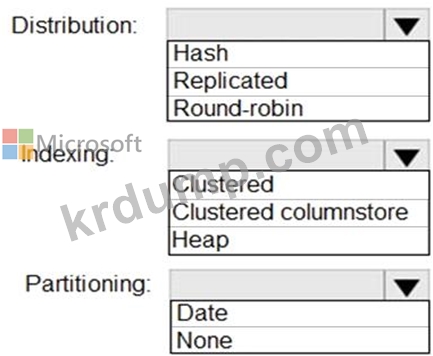
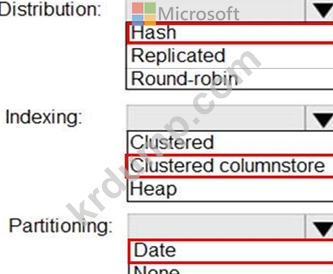
Azure Blob Storage에서 준비 테이블로 데이터를 로드할 계획입니다. 매일 약 100만 행의 데이터가 로드됩니다. 매일 로드하기 전에 테이블이 잘립니다.
스테이징 테이블을 생성해야 합니다. 솔루션은 데이터를 준비 테이블에 로드하는 데 걸리는 시간을 최소화해야 합니다.
테이블을 어떻게 구성해야 합니까? 응답하려면 응답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
DP-203 문제 89
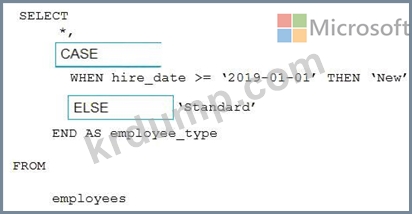
직원이라는 이름의 다음 테이블이 있습니다.

hire_date 값을 기준으로 employee_type 값을 계산해야 합니다.
Transact-SQL 문을 어떻게 완성해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 또는 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 드래그하거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
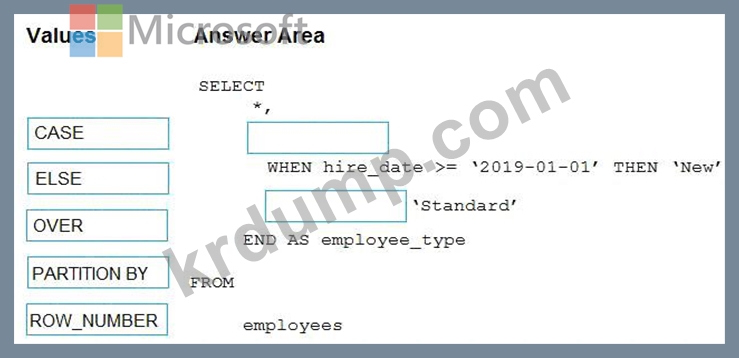
hire_date 값을 기준으로 employee_type 값을 계산해야 합니다.
Transact-SQL 문을 어떻게 완성해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 또는 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 드래그하거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203 문제 90
매핑 데이터 흐름을 포함할 Azure Data Factory 파이프라인을 만들 계획입니다.
중첩 배열이 있는 객체를 포함하는 JSON 데이터가 있습니다.
JSON 형식의 데이터를 테이블 형식의 데이터 세트로 변환해야 합니다. 데이터세트에는 배열의 각 항목에 대해 하나의 견인이 있어야 합니다.
매핑 데이터 흐름에서 어떤 변환 방법을 사용해야 합니까?
중첩 배열이 있는 객체를 포함하는 JSON 데이터가 있습니다.
JSON 형식의 데이터를 테이블 형식의 데이터 세트로 변환해야 합니다. 데이터세트에는 배열의 각 항목에 대해 하나의 견인이 있어야 합니다.
매핑 데이터 흐름에서 어떤 변환 방법을 사용해야 합니까?
DP-203 문제 91
Azure Synapse Analytics 전용 SQL Pool1이 있습니다. Pool1에는 dbo.Sales라는 분할된 사실 테이블과 일치하는 테이블 및 파티션 정의가 있는 stg.Sales라는 준비 테이블이 포함되어 있습니다.
dbo.Sales에 있는 첫 번째 파티션의 내용을 stg.Sales에 있는 동일한 파티션의 내용으로 덮어써야 합니다. 솔루션은 로드 시간을 최소화해야 합니다.
당신은 무엇을 해야 합니까?
dbo.Sales에 있는 첫 번째 파티션의 내용을 stg.Sales에 있는 동일한 파티션의 내용으로 덮어써야 합니다. 솔루션은 로드 시간을 최소화해야 합니다.
당신은 무엇을 해야 합니까?