
DP-203-KR 문제 1
Azure Databrick 클러스터에 대한 애플리케이션 메트릭, 스트리밍 쿼리 이벤트 및 애플리케이션 로그 메시지를 수집해야 합니다.
어떤 유형의 라이브러리 및 작업 영역을 구현해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
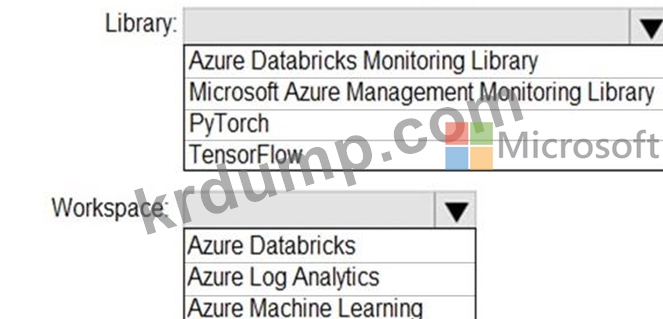
어떤 유형의 라이브러리 및 작업 영역을 구현해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203-KR 문제 2
고객용 JSON 파일이 포함된 Azure Data Lake Storage Gen2 계정이 있습니다. 파일에는 FirstName 및 LastName이라는 두 가지 특성이 포함되어 있습니다.
Azure Databricks를 사용하여 JSON 파일에서 Azure Synapse Analytics 테이블로 데이터를 복사해야 합니다. FirstName 및 LastName 값을 연결하는 새 열을 만들어야 합니다.
다음 구성 요소를 생성합니다.
Azure Synapse의 대상 테이블
Azure Blob 스토리지 컨테이너
서비스 주체
Databricks 노트북에서 다음에 순서대로 수행해야 하는 5가지 작업은 무엇인가요? 응답하려면 작업 목록에서 해당 작업을 응답 영역으로 이동하고 올바른 순서로 정렬하십시오.

Azure Databricks를 사용하여 JSON 파일에서 Azure Synapse Analytics 테이블로 데이터를 복사해야 합니다. FirstName 및 LastName 값을 연결하는 새 열을 만들어야 합니다.
다음 구성 요소를 생성합니다.
Azure Synapse의 대상 테이블
Azure Blob 스토리지 컨테이너
서비스 주체
Databricks 노트북에서 다음에 순서대로 수행해야 하는 5가지 작업은 무엇인가요? 응답하려면 작업 목록에서 해당 작업을 응답 영역으로 이동하고 올바른 순서로 정렬하십시오.

DP-203-KR 문제 3
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 하나 이상의 올바른 솔루션이 있을 수 있지만 다른 질문 세트에는 올바른 솔루션이 없을 수 있습니다.
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
계층 구조가 있는 Azure Databricks 작업 영역을 만들 계획입니다. 작업 영역에는 다음 세 가지 워크로드가 포함됩니다.
Python 및 SQL을 사용할 데이터 엔지니어를 위한 워크로드입니다.
Python, Scala 및 SOL을 사용하는 노트북을 실행할 작업에 대한 워크로드입니다.
데이터 과학자가 Scala 및 R에서 임시 분석을 수행하는 데 사용할 워크로드입니다.
회사의 엔터프라이즈 아키텍처 팀은 Databricks 환경에 대해 다음 표준을 식별합니다.
데이터 엔지니어는 클러스터를 공유해야 합니다.
작업 클러스터는 데이터 과학자와 데이터 엔지니어가 클러스터에 배포할 패키지 노트북을 제공하는 요청 프로세스를 사용하여 관리됩니다.
모든 데이터 과학자에게는 120분 동안 활동이 없으면 자동으로 종료되는 자체 클러스터가 할당되어야 합니다. 현재 세 명의 데이터 과학자가 있습니다.
워크로드에 대한 Databricks 클러스터를 만들어야 합니다.
솔루션: 각 데이터 과학자를 위한 표준 클러스터, 데이터 엔지니어를 위한 높은 동시성 클러스터 및 작업을 위한 높은 동시성 클러스터를 만듭니다.
이것이 목표를 달성합니까?
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
계층 구조가 있는 Azure Databricks 작업 영역을 만들 계획입니다. 작업 영역에는 다음 세 가지 워크로드가 포함됩니다.
Python 및 SQL을 사용할 데이터 엔지니어를 위한 워크로드입니다.
Python, Scala 및 SOL을 사용하는 노트북을 실행할 작업에 대한 워크로드입니다.
데이터 과학자가 Scala 및 R에서 임시 분석을 수행하는 데 사용할 워크로드입니다.
회사의 엔터프라이즈 아키텍처 팀은 Databricks 환경에 대해 다음 표준을 식별합니다.
데이터 엔지니어는 클러스터를 공유해야 합니다.
작업 클러스터는 데이터 과학자와 데이터 엔지니어가 클러스터에 배포할 패키지 노트북을 제공하는 요청 프로세스를 사용하여 관리됩니다.
모든 데이터 과학자에게는 120분 동안 활동이 없으면 자동으로 종료되는 자체 클러스터가 할당되어야 합니다. 현재 세 명의 데이터 과학자가 있습니다.
워크로드에 대한 Databricks 클러스터를 만들어야 합니다.
솔루션: 각 데이터 과학자를 위한 표준 클러스터, 데이터 엔지니어를 위한 높은 동시성 클러스터 및 작업을 위한 높은 동시성 클러스터를 만듭니다.
이것이 목표를 달성합니까?
DP-203-KR 문제 4
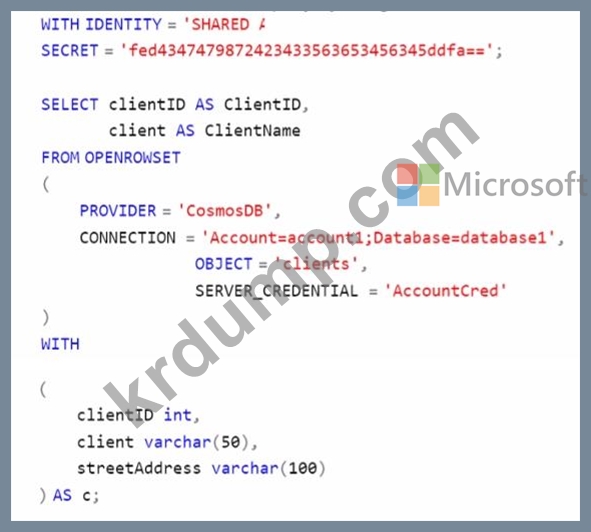
Azure Cosmos DB 분석 저장소와 WS 1이라는 Azure Synapse Analytics 작업 영역을 포함하는 Azure 구독이 있습니다. WS1에는 서버리스 SQL 풀 이름 Pool1이 있습니다.
Pool1을 사용하여 다음 쿼리를 실행합니다.
다음 각 진술에 대해 해당 진술이 참이면 예를 선택하십시오. 그렇지 않으면 아니요를 선택합니다.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.

Pool1을 사용하여 다음 쿼리를 실행합니다.
다음 각 진술에 대해 해당 진술이 참이면 예를 선택하십시오. 그렇지 않으면 아니요를 선택합니다.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.

DP-203-KR 문제 5
Table1이라는 테이블을 포함하는 SA1이라는 Azure Synapse Analytics 전용 SQL 풀이 있습니다. 삭제된 행의 비율이 높은 테이블을 식별해야 합니다. 무엇을 실행해야 합니까?