
DP-100 문제 1
특징 추출 방법을 선택해야 합니다.
어떤 방법을 사용해야 합니까?
어떤 방법을 사용해야 합니까?
DP-100 문제 2
TSV 파일 집합이 포함된 Azure Blob 컨테이너가 있습니다. Azure Blob 컨테이너는 Azure Machine Learning 서비스 작업 영역에 대한 데이터 저장소로 등록됩니다. 각 TSV 파일은 동일한 데이터 스키마를 사용합니다.
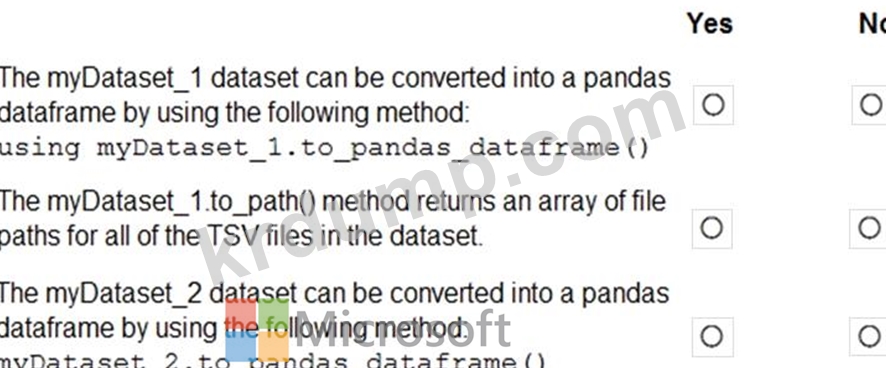
모든 TSV 파일에 대한 데이터를 함께 집계한 다음 Python용 Azure Machine Learning SDK를 사용하여 집계된 데이터를 Azure Machine Learning 작업 영역의 데이터 세트로 등록할 계획입니다.
다음 코드를 실행합니다.

다음 각 진술에 대해 진술이 참이면 예를 선택하십시오. 그렇지 않으면 아니요를 선택합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
모든 TSV 파일에 대한 데이터를 함께 집계한 다음 Python용 Azure Machine Learning SDK를 사용하여 집계된 데이터를 Azure Machine Learning 작업 영역의 데이터 세트로 등록할 계획입니다.
다음 코드를 실행합니다.
다음 각 진술에 대해 진술이 참이면 예를 선택하십시오. 그렇지 않으면 아니요를 선택합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-100 문제 3
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 하나 이상의 올바른 솔루션이 있을 수 있지만 다른 질문 세트에는 올바른 솔루션이 없을 수 있습니다.
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
로지스틱 회귀 알고리즘을 사용하여 분류 모델을 교육합니다.
전체 글로벌 상대 중요도 값과 특정 예측 집합에 대한 로컬 중요도 측정값으로 각 기능의 중요도를 계산하여 모델의 예측을 설명할 수 있어야 합니다.
필요한 전역 및 로컬 기능 중요도 값을 검색하는 데 사용할 수 있는 설명자를 만들어야 합니다.
해결 방법: TabularExplainer를 만듭니다.
솔루션이 목표를 충족합니까?
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
로지스틱 회귀 알고리즘을 사용하여 분류 모델을 교육합니다.
전체 글로벌 상대 중요도 값과 특정 예측 집합에 대한 로컬 중요도 측정값으로 각 기능의 중요도를 계산하여 모델의 예측을 설명할 수 있어야 합니다.
필요한 전역 및 로컬 기능 중요도 값을 검색하는 데 사용할 수 있는 설명자를 만들어야 합니다.
해결 방법: TabularExplainer를 만듭니다.
솔루션이 목표를 충족합니까?

DP-100 문제 4
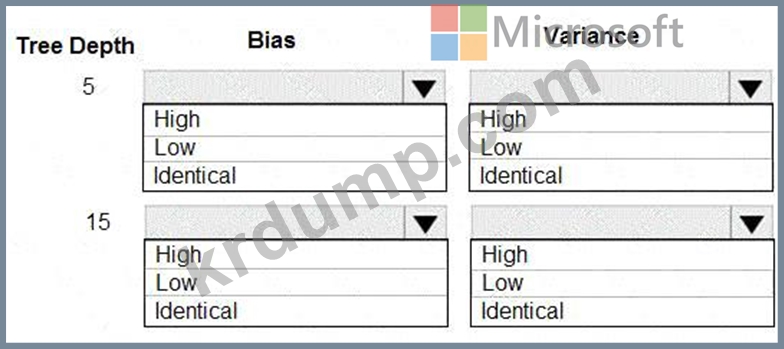
의사 결정 트리 알고리즘을 사용하고 있습니다. 다음과 같은 트리 깊이에서 잘 일반화되는 모델을 훈련했습니다.
10.
다양한 트리 깊이 값을 사용하여 모델의 편향 및 분산 속성을 선택해야 합니다.
각 트리 깊이에 대해 어떤 속성을 선택해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
10.
다양한 트리 깊이 값을 사용하여 모델의 편향 및 분산 속성을 선택해야 합니다.
각 트리 깊이에 대해 어떤 속성을 선택해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.


DP-100 문제 5
오픈 소스 딥 러닝 프레임워크인 Caffe2 및 Theano와 함께 DSVM(Data Science Virtual Machine)을 사용할 계획입니다. 프레임워크를 지원하려면 미리 구성된 DSVM을 선택해야 합니다.
무엇을 만들어야 합니까?
무엇을 만들어야 합니까?