
Databricks-Certified-Professional-Data-Scientist 문제 1
마리는 내일 사막에서 열리는 야외 결혼식에서 결혼합니다. 최근에는 일년에 단 5일만 비가 내립니다. 불행히도 기상캐스터는 내일 비를 예보했다. 실제로 비가 오면 기상캐스터는 90%의 확률로 비를 정확하게 예측합니다. 비가 오지 않을 때 그는 10%의 확률로 비를 잘못 예측합니다. 다음 중 Marie의 결혼식 날 비가 올지 여부를 계산하는 데 사용하는 것은?
Databricks-Certified-Professional-Data-Scientist 문제 2
전시를 참고하세요.
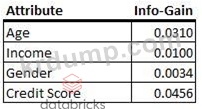
의사 결정 트리를 만들고 있습니다. 이 전시에서는 4개의 변수가 각각의 정보 이득 값과 함께 나열됩니다.
이 정보를 기반으로 다음 분할이 의사 결정 트리에 있을 것으로 예상되는 속성은 무엇입니까?
의사 결정 트리를 만들고 있습니다. 이 전시에서는 4개의 변수가 각각의 정보 이득 값과 함께 나열됩니다.
이 정보를 기반으로 다음 분할이 의사 결정 트리에 있을 것으로 예상되는 속성은 무엇입니까?
Databricks-Certified-Professional-Data-Scientist 문제 3
앞면이 나올 확률이 p이고 p가 알려지지 않은 상태에서 우리의 목표는 p를 추정하는 것입니다. 명백한 접근 방식은 동전이 앞면이 나온 횟수를 세고 총 동전 던지기로 나누는 것입니다. 동전을 1000번 던지고 앞면이 367번 나온다면 p는 약 0.367로 추정하는 것이 매우 합리적입니다. 그러나 동전을 두 번만 던졌고 두 번 모두 앞면이 나왔다고 가정해 보겠습니다.
p를 1.0으로 추정하는 것이 합리적입니까? 직관적으로 우리가 동전을 두 번만 던졌을 때, 동전이 항상 앞면이 나올 것이라고 결론짓는 것은 다소 성급한 것 같고, ____________는 그러한 성급한 결론을 피하는 방법입니다.
p를 1.0으로 추정하는 것이 합리적입니까? 직관적으로 우리가 동전을 두 번만 던졌을 때, 동전이 항상 앞면이 나올 것이라고 결론짓는 것은 다소 성급한 것 같고, ____________는 그러한 성급한 결론을 피하는 방법입니다.
Databricks-Certified-Professional-Data-Scientist 문제 4
결합 분포가 이미 알려진 두 개의 확률 변수 X와 Y가 있다고 가정하고 X의 한계 분포는 단순히 Y에 대한 정보에 대한 평균을 내는 X의 확률 분포입니다.
Y 값을 모를 때 X의 확률 분포입니다. 그렇다면 X의 한계 분포를 어떻게 계산합니까?
Y 값을 모를 때 X의 확률 분포입니다. 그렇다면 X의 한계 분포를 어떻게 계산합니까?
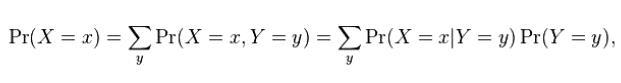
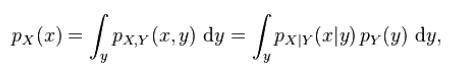
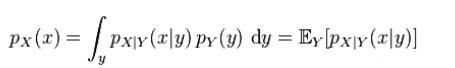

Databricks-Certified-Professional-Data-Scientist 문제 5
데이터 과학자는 세 가지 위험 요소인 연령, 성별, 혈중 콜레스테롤 수치를 기반으로 심장병으로 인한 사망 확률을 예측하려고 합니다. 이 프로젝트에 가장 적절한 방법은 무엇입니까?