
QSDA2022 문제 1
회사는 매일 1GB의 발권 데이터를 생성합니다. 데이터는 다중 테이블에 저장됩니다. 비즈니스 사용자는 과거에 처리된 티켓의 추세를 확인해야 합니다. 2년 사용자는 특정 날짜의 트랜잭션 수준 데이터에 거의 액세스하지 않습니다. 지난 2년간의 데이터(720GB 데이터)만 로드해야 합니다. 데이터 설계자는 이러한 요구 사항을 충족하기 위해 어떤 방법을 사용해야 합니까?
QSDA2022 문제 2
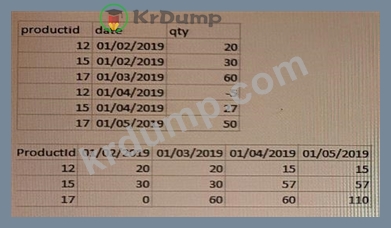
전시물을 참고하세요.
첫 번째 테이블은 소스 테이블(Original table)을 보여줍니다.
이 데이터는 각 제품에 대해 매월 저장된 재고를 나타냅니다.
* 관련 필드는 productid, qty 및 date입니다.
* 날짜 필드는 다음을 사용하여 달력 월을 나타냅니다.
* qty 항목은 당월 대비 전월 대비 상품 재고 변동을 나타냅니다. 월 사이에 변동이 없으면 테이블에 새 항목이 없습니다.
두 번째 테이블은 데이터 분석가가 각 제품별로 사용 가능한 재고의 월별 추세를 표시하는 앱에서 생성해야 하는 피벗 테이블 시각화를 보여줍니다.
성능상의 이유로 데이터 분석가는 스크립트에서 매월 각 제품의 실행 중인 재고 수량을 계산하도록 데이터 설계자에게 요청합니다.
데이터 설계자는 어떤 접근 방식을 사용해야 합니까?
QSDA2022 문제 3
전시회를 참조하십시오.
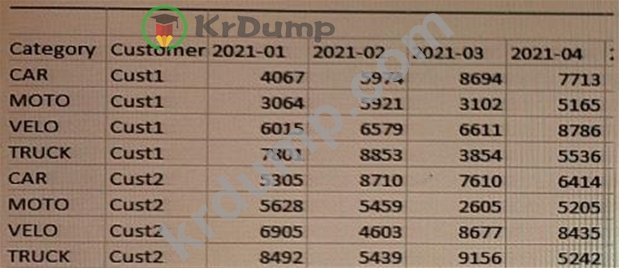
고객은 Excel 파일에서 예측 데이터를 로드해야 합니다.
데이터 설계자가 데이터를 로드하기 위해 사용해야 하는 선행 load 문은 무엇입니까?
고객은 Excel 파일에서 예측 데이터를 로드해야 합니다.
데이터 설계자가 데이터를 로드하기 위해 사용해야 하는 선행 load 문은 무엇입니까?
QSDA2022 문제 4
전시회를 참조하십시오.

데이터 설계자는 판매 데이터를 로드하고 2018년과 2019년에 구매한 고객만 표시하는 테이블을 생성합니다. 데이터 설계자는 판매 측정에 다음 세트 분석 표현식을 적용합니다.
개수<{<Year={'2 018'}, CustomerID=P({<Year={'2019*}>})>} 고객 ID)
식을 적용한 후 결과 테이블을 표시하는 옵션은 무엇입니까?
A)
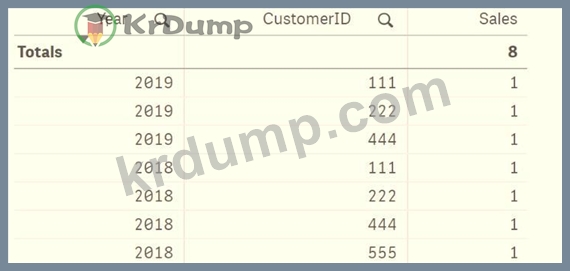
B)

C)
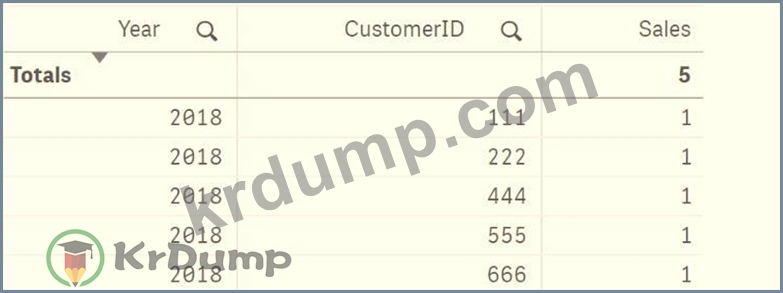
D)

데이터 설계자는 판매 데이터를 로드하고 2018년과 2019년에 구매한 고객만 표시하는 테이블을 생성합니다. 데이터 설계자는 판매 측정에 다음 세트 분석 표현식을 적용합니다.
개수<{<Year={'2 018'}, CustomerID=P({<Year={'2019*}>})>} 고객 ID)
식을 적용한 후 결과 테이블을 표시하는 옵션은 무엇입니까?
A)
B)
C)
D)
QSDA2022 문제 5
전시회를 참조하십시오.
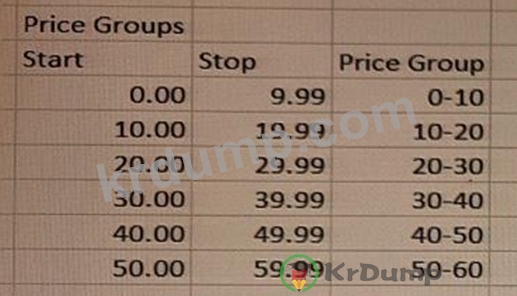
데이터 설계자는 각 제품을 가격 그룹으로 분류해야 합니다. 가격 그룹은 기본적으로 동일한 너비여야 하며 사용자가 분석 중에 버킷의 너비를 동적으로 변경할 수 있습니다.
이러한 요구 사항을 충족하기 위해 데이터 설계자는 어떤 기능을 사용해야 합니까?
데이터 설계자는 각 제품을 가격 그룹으로 분류해야 합니다. 가격 그룹은 기본적으로 동일한 너비여야 하며 사용자가 분석 중에 버킷의 너비를 동적으로 변경할 수 있습니다.
이러한 요구 사항을 충족하기 위해 데이터 설계자는 어떤 기능을 사용해야 합니까?