
DP-203 문제 76
한 회사는 PaaS(Platform-as-a-Service)를 사용하여 새로운 데이터 파이프라인 프로세스를 만들 계획입니다. 프로세스는 다음 요구 사항을 충족해야 합니다.
섭취:
여러 데이터 소스에 액세스하세요.
워크플로를 조정하는 기능을 제공합니다.
SQL Server Integration Services 패키지를 실행하는 기능을 제공합니다.
가게:
빅데이터 워크로드에 맞게 스토리지를 최적화하세요.
저장 데이터의 암호화를 제공합니다.
크기 제한 없이 작동합니다.
준비 및 훈련:
탐색 및 시각화를 위한 완벽하게 관리되는 대화형 작업 공간을 제공합니다.
R, SQL, Python, Scala 및 Java로 프로그래밍할 수 있는 기능을 제공합니다.
Azure Active Directory를 통해 원활한 사용자 인증을 제공하세요.
모델 & 서브:
기본 열 형식 스토리지를 구현합니다.
SQL 언어 지원
구조화된 스트리밍을 지원합니다.
데이터 통합 파이프라인을 구축해야 합니다.
어떤 기술을 사용해야 합니까? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.

섭취:
여러 데이터 소스에 액세스하세요.
워크플로를 조정하는 기능을 제공합니다.
SQL Server Integration Services 패키지를 실행하는 기능을 제공합니다.
가게:
빅데이터 워크로드에 맞게 스토리지를 최적화하세요.
저장 데이터의 암호화를 제공합니다.
크기 제한 없이 작동합니다.
준비 및 훈련:
탐색 및 시각화를 위한 완벽하게 관리되는 대화형 작업 공간을 제공합니다.
R, SQL, Python, Scala 및 Java로 프로그래밍할 수 있는 기능을 제공합니다.
Azure Active Directory를 통해 원활한 사용자 인증을 제공하세요.
모델 & 서브:
기본 열 형식 스토리지를 구현합니다.
SQL 언어 지원
구조화된 스트리밍을 지원합니다.
데이터 통합 파이프라인을 구축해야 합니다.
어떤 기술을 사용해야 합니까? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.


DP-203 문제 77
Azure Databricks의 Delta Lake에 있는 테이블을 사용할 2개의 솔루션을 설계하고 있습니다.
다음을 수행하는 데 걸리는 시간을 최소화해야 합니다.
*파티션되지 않은 테이블에 대한 쿼리
* 분할되지 않은 열에 대한 조인
솔루션에 어떤 두 가지 옵션을 포함해야 합니까? 각 정답은 솔루션의 일부를 나타냅니다.
(Microsoft Azure의 데이터 엔지니어링을 기반으로 답변을 뒷받침하기 위해 정답을 선택하고 설명 및 참조 제공)
다음을 수행하는 데 걸리는 시간을 최소화해야 합니다.
*파티션되지 않은 테이블에 대한 쿼리
* 분할되지 않은 열에 대한 조인
솔루션에 어떤 두 가지 옵션을 포함해야 합니까? 각 정답은 솔루션의 일부를 나타냅니다.
(Microsoft Azure의 데이터 엔지니어링을 기반으로 답변을 뒷받침하기 위해 정답을 선택하고 설명 및 참조 제공)
DP-203 문제 78
Azure Databricks를 사용하여 DBTBL1이라는 데이터 세트를 개발합니다.
DBTBL1에는 다음 열이 포함되어 있습니다.
* 센서 유형D
* 지리지역ID
* 년도
* 월
* 낮
* 시간
* 분
* 온도
* 바람 속도
* 다른
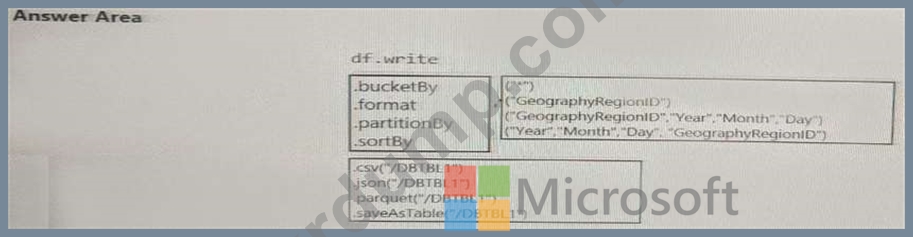
각 GeographyRegionID에 따라 달라지는 일일 증분 로드 파이프라인을 지원하려면 데이터를 저장해야 합니다.
솔루션은 스토리지 비용을 최소화해야 합니다.
코드를 어떻게 완성해야 할까요? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.
DBTBL1에는 다음 열이 포함되어 있습니다.
* 센서 유형D
* 지리지역ID
* 년도
* 월
* 낮
* 시간
* 분
* 온도
* 바람 속도
* 다른
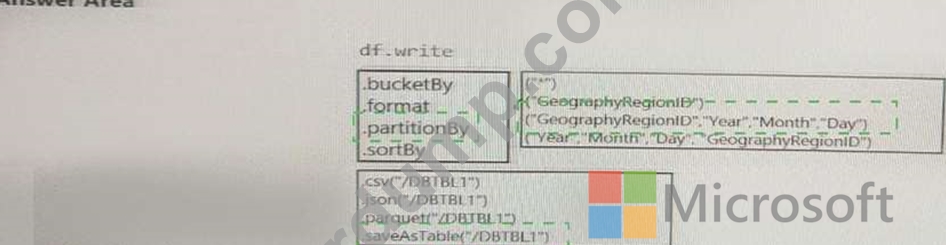
각 GeographyRegionID에 따라 달라지는 일일 증분 로드 파이프라인을 지원하려면 데이터를 저장해야 합니다.
솔루션은 스토리지 비용을 최소화해야 합니다.
코드를 어떻게 완성해야 할까요? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.
DP-203 문제 79
작업 영역1이라는 Azure Synapse Analytics 작업 영역이 포함된 Azure 구독이 있습니다.
Workspace1에는 SQL Pool이라는 전용 SQL 풀과 Sparkpool이라는 Apache Spark 풀이 포함되어 있습니다.
Sparkpool1에는 pyspark.df라는 DataFrame이 포함되어 있습니다.
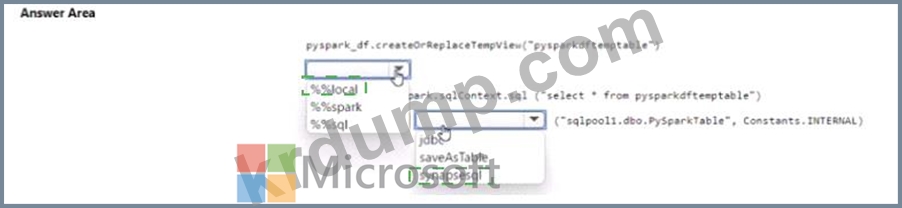
PySpark 노트북을 사용하여 SQLPooM의 탭에 pyspark_df의 내용을 작성해야 합니다.
코드를 어떻게 완성해야 할까요? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.

Workspace1에는 SQL Pool이라는 전용 SQL 풀과 Sparkpool이라는 Apache Spark 풀이 포함되어 있습니다.
Sparkpool1에는 pyspark.df라는 DataFrame이 포함되어 있습니다.
PySpark 노트북을 사용하여 SQLPooM의 탭에 pyspark_df의 내용을 작성해야 합니다.
코드를 어떻게 완성해야 할까요? 답변하려면 답변 영역에서 적절한 옵션을 선택하세요.
참고: 올바른 선택은 각각 1점의 가치가 있습니다.

DP-203 문제 80
Azure Data Lake Storage Gen2 컨테이너에 파일을 저장합니다. 컨테이너에는 다음 그림에 표시된 스토리지 정책이 있습니다.

드롭다운 메뉴를 사용하여 그래픽에 표시된 정보를 기반으로 각 문항을 완성하는 답변 선택을 선택하세요.
참고: 올바른 선택마다 1점의 가치가 있습니다.

드롭다운 메뉴를 사용하여 그래픽에 표시된 정보를 기반으로 각 문항을 완성하는 답변 선택을 선택하세요.
참고: 올바른 선택마다 1점의 가치가 있습니다.
