
DP-203-KR 문제 11
Azure Synapse Analytics 전용 SQL 풀이 있습니다.
풀의 데이터가 유휴 상태에서 암호화되었는지 확인해야 합니다. 솔루션은 데이터를 쿼리하는 애플리케이션을 수정할 필요가 없어야 합니다.
어떻게 해야 합니까?
풀의 데이터가 유휴 상태에서 암호화되었는지 확인해야 합니다. 솔루션은 데이터를 쿼리하는 애플리케이션을 수정할 필요가 없어야 합니다.
어떻게 해야 합니까?
DP-203-KR 문제 12
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 하나 이상의 올바른 솔루션이 있을 수 있지만 다른 질문 세트에는 올바른 솔루션이 없을 수 있습니다.
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
Twitter 데이터를 분석할 Azure Stream Analytics 솔루션을 설계하고 있습니다.
각 10초 창에서 트윗 수를 계산해야 합니다. 솔루션은 각 트윗이 한 번만 계산되도록 해야 합니다.
솔루션: 5초의 홉 크기와 10초의 창 크기를 사용하는 호핑 창을 사용합니다.
이것이 목표를 달성합니까?
이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 결과적으로 이러한 질문은 검토 화면에 나타나지 않습니다.
Twitter 데이터를 분석할 Azure Stream Analytics 솔루션을 설계하고 있습니다.
각 10초 창에서 트윗 수를 계산해야 합니다. 솔루션은 각 트윗이 한 번만 계산되도록 해야 합니다.
솔루션: 5초의 홉 크기와 10초의 창 크기를 사용하는 호핑 창을 사용합니다.
이것이 목표를 달성합니까?
DP-203-KR 문제 13
Pool1이라는 Azure Synapse Analytics 서버리스 SQL 풀과 storage1이라는 Azure Data Lake Storage Gen2 계정이 있습니다. AllowedBlobpublicAccess 속성은 storage1에 대해 비활성화됩니다.
Azure AD(Azure Active Directory) 사용자가 Pool1에서 storage1에 액세스하는 데 사용할 수 있는 외부 데이터 원본을 만들어야 합니다.
무엇을 먼저 만들어야 할까요?
Azure AD(Azure Active Directory) 사용자가 Pool1에서 storage1에 액세스하는 데 사용할 수 있는 외부 데이터 원본을 만들어야 합니다.
무엇을 먼저 만들어야 할까요?
DP-203-KR 문제 14
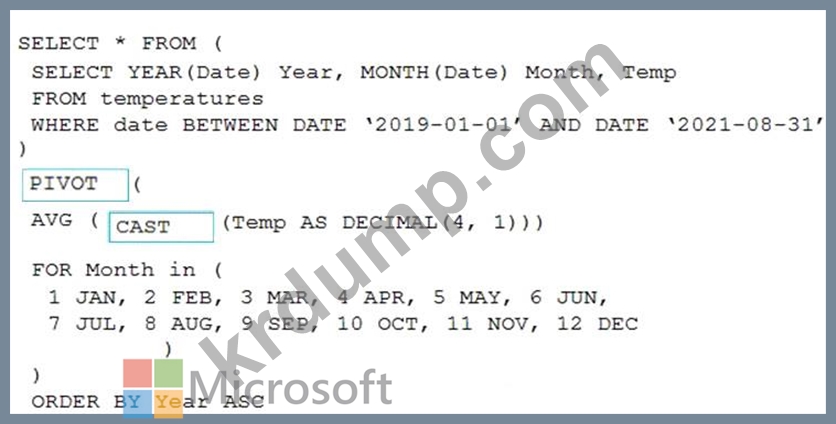
온도라는 Apache Spark DataFrame이 있습니다. 데이터 샘플은 다음 표에 나와 있습니다.

Spark SQL 쿼리를 사용하여 다음 테이블을 생성해야 합니다.

쿼리를 어떻게 완료해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

Spark SQL 쿼리를 사용하여 다음 테이블을 생성해야 합니다.
쿼리를 어떻게 완료해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203-KR 문제 15
Azure Data Lake Storage Gen 2 계정을 사용하여 요금소의 페타바이트 번호판 사진을 저장하는 애플리케이션을 설계하고 있습니다. 계정은 영역 중복 스토리지(ZRS)를 사용합니다.
다음 사용 패턴을 식별합니다.
* 데이터가 생성된 후 처음 30일 동안 하루에 여러 번 데이터에 액세스합니다. 데이터는 99.9%의 가용성 SU를 충족해야 합니다.
* 90일 이후에는 데이터에 자주 액세스하지 않지만 30초 이내에 사용할 수 있어야 합니다.
* 365일 이후에는 데이터에 자주 액세스하지 않지만 5분 이내에 사용할 수 있어야 합니다.

다음 사용 패턴을 식별합니다.
* 데이터가 생성된 후 처음 30일 동안 하루에 여러 번 데이터에 액세스합니다. 데이터는 99.9%의 가용성 SU를 충족해야 합니다.
* 90일 이후에는 데이터에 자주 액세스하지 않지만 30초 이내에 사용할 수 있어야 합니다.
* 365일 이후에는 데이터에 자주 액세스하지 않지만 5분 이내에 사용할 수 있어야 합니다.
