
DP-203-KR 문제 16
Azure Synapse 서버리스 SQL 풀이 있습니다.
OPENROWSET 함수를 사용하여 파일에서 JSON 문서를 읽어야 합니다.
쿼리를 어떻게 완료해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

OPENROWSET 함수를 사용하여 파일에서 JSON 문서를 읽어야 합니다.
쿼리를 어떻게 완료해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203-KR 문제 17
다음 전시회에 표시된 Azure Data Factory 파이프라인이 있습니다.

첫 번째 파이프라인 실행에 대한 실행 로그는 다음 전시회에 표시됩니다.
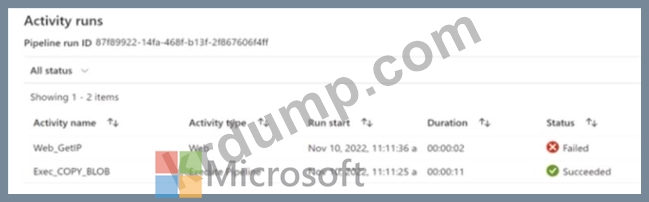
두 번째 파이프라인 실행에 대한 실행 로그는 다음 그림에 나와 있습니다.

다음 각 진술에 대해 진술이 참이면 예를 선택하십시오. 그렇지 않으면 아니오를 선택하십시오. 참고: 각 올바른 선택은 1점의 가치가 있습니다.

첫 번째 파이프라인 실행에 대한 실행 로그는 다음 전시회에 표시됩니다.
두 번째 파이프라인 실행에 대한 실행 로그는 다음 그림에 나와 있습니다.
다음 각 진술에 대해 진술이 참이면 예를 선택하십시오. 그렇지 않으면 아니오를 선택하십시오. 참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203-KR 문제 18
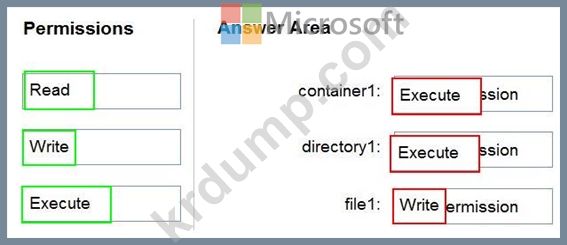
storage1이라는 Azure Data Lake Storage Gen2 계정이 포함된 Azure 구독이 있습니다. Storage1에는 container1이라는 컨테이너가 있습니다. Container1에는 directory1이라는 디렉터리가 있습니다. Directory1에는 file1이라는 파일이 있습니다.
storage1에 대한 Storage Blob 데이터 판독기 역할이 할당된 User1이라는 Azure AD(Azure Active Directory) 사용자가 있습니다.
User1이 file1에 데이터를 추가할 수 있는지 확인해야 합니다. 솔루션은 최소 권한 원칙을 사용해야 합니다.
어떤 권한을 부여해야 합니까? 응답하려면 적절한 권한을 올바른 리소스로 드래그하세요. 각 권한은 한 번, 두 번 이상 사용하거나 전혀 사용하지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.

storage1에 대한 Storage Blob 데이터 판독기 역할이 할당된 User1이라는 Azure AD(Azure Active Directory) 사용자가 있습니다.
User1이 file1에 데이터를 추가할 수 있는지 확인해야 합니다. 솔루션은 최소 권한 원칙을 사용해야 합니다.
어떤 권한을 부여해야 합니까? 응답하려면 적절한 권한을 올바른 리소스로 드래그하세요. 각 권한은 한 번, 두 번 이상 사용하거나 전혀 사용하지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
DP-203-KR 문제 19
Storage1 및 Storage2라는 두 개의 Azure Storage 계정이 있습니다. 각 계정에는 하나의 컨테이너가 있으며 계층적 네임스페이스가 활성화되어 있습니다. 시스템에는 Apache Parquet 형식으로 저장된 데이터가 포함된 파일이 있습니다.
Data Factory 복사 활동을 사용하여 Storage1에서 Storage2로 폴더 및 파일을 복사해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다.
어떠한 변환도 수행되지 않아야 합니다.
원래 폴더 구조를 유지해야 합니다.
복사 작업을 수행하는 데 필요한 시간을 최소화합니다.
복사 활동을 어떻게 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

Data Factory 복사 활동을 사용하여 Storage1에서 Storage2로 폴더 및 파일을 복사해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다.
어떠한 변환도 수행되지 않아야 합니다.
원래 폴더 구조를 유지해야 합니다.
복사 작업을 수행하는 데 필요한 시간을 최소화합니다.
복사 활동을 어떻게 구성해야 합니까? 대답하려면 대답 영역에서 적절한 옵션을 선택하십시오.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

DP-203-KR 문제 20
온도라는 Apache Spark DataFrame이 있습니다. 데이터 샘플은 다음 표에 나와 있습니다.

Spark SQL 쿼리를 사용하여 다음 테이블을 생성해야 합니다.

쿼리를 어떻게 완료해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.

Spark SQL 쿼리를 사용하여 다음 테이블을 생성해야 합니다.
쿼리를 어떻게 완료해야 합니까? 응답하려면 적절한 값을 올바른 대상으로 드래그하십시오. 각 값은 한 번, 두 번 이상 사용되거나 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
