
DP-201 문제 21
무엇을 추천해야 할까요?
스토리지는 데이터베이스 OLTP 워크로드에 최적화된 스토리지로 구성되어야 합니다.
Azure SQL Database는 성능 향상에 의미 있는 방식으로 기여할 수 있는 세 가지 기본 인메모리 기반 기능(기본 데이터베이스 엔진에 내장)을 제공합니다.
메모리 내 OLTP(온라인 트랜잭션 처리)
주로 OLAP(온라인 분석 처리) 워크로드용으로 설계된 클러스터형 columnstore 인덱스 HTAP(하이브리드 트랜잭션/분석 처리) 워크로드용으로 설계된 비클러스터형 columnstore 인덱스 참조:
https://www.databasejournal.com/features/mssql/overview-of-in-memory-technologies-of-azure-sql-database.html 데이터 처리 솔루션 설계 Testlet 4 사례 연구 사례 연구입니다. 사례 연구는 별도로 시간이 지정되지 않습니다. 각 사례를 완료하고 싶은 만큼 시험 시간을 사용할 수 있습니다. 그러나 이 시험에 추가 사례 연구 및 섹션이 있을 수 있습니다. 주어진 시간 내에 이 시험에 포함된 모든 문제를 완료할 수 있도록 시간을 관리해야 합니다.
사례 연구에 포함된 질문에 답하려면 사례 연구에 제공된 정보를 참조해야 합니다. 사례 연구에는 사례 연구에 설명된 시나리오에 대한 추가 정보를 제공하는 전시 및 기타 리소스가 포함될 수 있습니다. 각 질문은 이 사례 연구의 다른 질문과 독립적입니다.
이 사례 연구가 끝나면 검토 화면이 나타납니다. 이 화면에서 답을 검토하고 시험의 다음 섹션으로 이동하기 전에 변경할 수 있습니다. 새 섹션을 시작한 후에는 이 섹션으로 돌아갈 수 없습니다.
사례 연구를 시작하려면
이 사례 연구의 첫 번째 질문을 표시하려면 다음 버튼을 클릭하십시오. 질문에 답하기 전에 왼쪽 창에 있는 버튼을 사용하여 사례 연구의 내용을 탐색하십시오. 이 버튼을 클릭하면 비즈니스 요구 사항, 기존 환경 및 문제 설명과 같은 정보가 표시됩니다. 사례 연구에 모든 정보 탭이 있는 경우 표시되는 정보는 후속 탭에 표시되는 정보와 동일합니다. 질문에 답할 준비가 되면 질문 버튼을 클릭하여 질문으로 돌아갑니다.
개요
일반 개요
ADatum Corporation은 미국 전역의 300개 이상의 병원에 5,000명의 의사가 있는 의료 회사입니다. 회사에는 의료 부서, 영업 부서, 마케팅 부서, 의료 연구 부서 및 인사 부서가 있습니다.
ADatum의 애플리케이션 환경을 재설계하고 있습니다.
물리적 위치
ADatum은 뉴욕, 댈러스, 로스앤젤레스에 3개의 주요 사무실을 두고 있습니다. 사무실은 WAN 링크를 사용하여 서로 연결됩니다. 각 사무실은 인터넷에 직접 연결됩니다. 로스앤젤레스 사무실에는 회사의 모든 애플리케이션을 호스팅하는 데이터 센터도 있습니다.
기존 환경
건강 검토
ADatum에는 의사가 청구, 환자 치료 및 전반적인 의사 모범 사례를 추적하는 데 사용하는 Health Review라는 중요한 OLTP 웹 응용 프로그램이 있습니다.
건강 인터페이스
ADatum에는 환자 관리 및 상태 업데이트와 관련된 병원 메시지를 수신하는 Health Interface라는 중요한 응용 프로그램이 있습니다. 메시지는 VPN을 사용하여 각 병원의 ERM(Enterprise Relationship Management) 시스템에서 일괄 전송됩니다. 각 병원에서 보낸 데이터는 다양한 열과 형식을 가질 수 있습니다.
현재 사용자 지정 C# 응용 프로그램은 데이터를 Health Interface로 보내는 데 사용됩니다. 애플리케이션은 더 이상 사용되지 않는 라이브러리를 사용하며 이 기능을 위한 새 솔루션을 설계해야 합니다.
건강 인사이트
ADatum에는 의사와 비즈니스 사용자에게 병원 및 환자 통찰력을 보여주는 Health Insights라는 웹 기반 보고 시스템이 있습니다. 데이터는 수동 입력뿐만 아니라 상태 검토 및 상태 인터페이스의 데이터에서 생성됩니다.
데이터베이스 플랫폼
현재 세 가지 애플리케이션의 데이터베이스는 Microsoft SQL Server 2012의 단일 인스턴스가 있는 오래된 VMware 클러스터에서 호스팅됩니다.
문제 설명
ADatum은 현재 환경에서 다음과 같은 문제를 식별합니다.
* 시간이 지남에 따라 Health Interface가 병원에서 수신하는 데이터가 느려지고 메시지 수가 증가했습니다.
* ADatum에 신규 병원 가입 시 데이터 표준화가 이루어지지 않아 Health Interface에서 스키마 수정이 필요함.
* 일괄 데이터 처리 속도가 일정하지 않습니다.
비즈니스 요구 사항
사업 목표
ADatum은 다음과 같은 비즈니스 목표를 식별합니다.
* 가능할 때마다 애플리케이션을 Azure로 마이그레이션합니다.
* 데이터 이동을 수행하는 데 필요한 개발 노력을 최소화합니다.
* 개발, 테스트 및 프로덕션 환경을 위한 지속적인 통합 및 배포를 제공합니다.
* 애플리케이션 및 데이터에 대한 더 빠른 액세스를 제공하고 보다 일관된 애플리케이션 성능을 제공합니다.
* 데이터 처리, 개발, 스케줄링, 모니터링 및 파이프라인 운영을 수행하는 데 필요한 서비스 수를 최소화합니다.
건강 심사 요건
ADatum은 상태 검토 애플리케이션에 대한 다음 요구 사항을 식별합니다.
* 민감한 건강 데이터가 저장 및 전송 중에 암호화되었는지 확인합니다.
* 건강 검토에서 모든 민감한 건강 데이터에 태그를 지정하십시오. 데이터는 감사에 사용됩니다.
상태 인터페이스 요구 사항
ADatum은 Health Interface 애플리케이션에 대한 다음 요구 사항을 식별합니다.
* 데이터 쓰기를 위한 유연한 스키마와 증가된 처리량을 제공하는 데이터 스토리지 솔루션으로 업그레이드하십시오. 데이터는 지역적으로 각 병원에서 가까운 위치에 있어야 하며 읽기는 항목의 가장 최근 커밋된 버전으로 표시되어야 합니다.
* 새로운 병원의 데이터를 Health Interface에 추가하는 데 걸리는 시간을 줄입니다.
* Azure에서 보다 확장 가능한 일괄 처리 솔루션을 지원합니다.
* 기존 SQL 쿼리를 다시 작성하기 위한 개발 노력의 양을 줄입니다.
건강 인사이트 요구 사항
ADatum은 Health Insights 애플리케이션에 대한 다음 요구 사항을 식별합니다.
* 이벤트 분석은 조직 날짜 차원 테이블을 사용하여 시간 경과에 따라 수행해야 합니다.
* Health Interface 및 Health Review의 데이터는 커밋 후 15분 이내에 Health Insights에서 사용할 수 있어야 합니다.
* 새로운 Health Insights 애플리케이션은 대규모 팩트 테이블에서 고성능 조인을 지원하는 대규모 병렬 처리(MPP) 아키텍처를 기반으로 구축되어야 합니다.
DP-201 문제 22
무엇을 추천해야 할까요?
DP-201 문제 23
무엇을 추천해야 할까요? 대답하려면 적절한 기술을 올바른 위치로 드래그하십시오. 각 기술은 한 번, 두 번 이상 또는 전혀 사용되지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 드래그하거나 스크롤해야 할 수 있습니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.


설명

상자 1: 코스모스 DB 인덱스
Backtrack에 대한 보고서는 가능한 한 빨리 실행되어야 합니다.
Azure Cosmos 컨테이너에서 기본 인덱싱 정책을 재정의할 수 있습니다. 이는 쿼리 성능을 향상시키거나 사용되는 스토리지를 줄이기 위해 인덱싱 정밀도를 조정하려는 경우에 유용할 수 있습니다.
상자 2: 코스모스 DB TTL
이 솔루션은 특정 차량 번호판과 관련된 모든 데이터를 보고합니다. 보고서는 SensorData 컬렉션의 데이터를 사용해야 합니다. 사용자는 다음과 같은 방법으로 차량 데이터를 필터링할 수 있어야 합니다.
* 특정 도로의 차량
* 제한 속도 이상으로 운전하는 차량
참고: TTL(Time to Live)을 사용하면 Azure Cosmos DB는 특정 기간 후에 컨테이너에서 항목을 자동으로 삭제하는 기능을 제공합니다. 기본적으로 컨테이너 수준에서 TTL을 설정하고 항목별로 값을 재정의할 수 있습니다. 컨테이너 또는 항목 수준에서 TTL을 설정한 후 Azure Cosmos DB는 마지막으로 수정된 시간 이후 기간이 지나면 이러한 항목을 자동으로 제거합니다.
DP-201 문제 24
무엇을 추천해야 할까요?
데이터 처리 솔루션 설계
테스트렛 2
사례 연구
이것은 사례 연구입니다. 사례 연구는 별도로 시간이 지정되지 않습니다. 각 사례를 완료하고 싶은 만큼 시험 시간을 사용할 수 있습니다. 그러나 이 시험에 추가 사례 연구 및 섹션이 있을 수 있습니다. 주어진 시간 내에 이 시험에 포함된 모든 문제를 완료할 수 있도록 시간을 관리해야 합니다.
사례 연구에 포함된 질문에 답하려면 사례 연구에 제공된 정보를 참조해야 합니다. 사례 연구에는 사례 연구에 설명된 시나리오에 대한 추가 정보를 제공하는 전시 및 기타 리소스가 포함될 수 있습니다. 각 질문은 이 사례 연구의 다른 질문과 독립적입니다.
이 사례 연구가 끝나면 검토 화면이 나타납니다. 이 화면에서 답을 검토하고 시험의 다음 섹션으로 이동하기 전에 변경할 수 있습니다. 새 섹션을 시작한 후에는 이 섹션으로 돌아갈 수 없습니다.
사례 연구를 시작하려면
이 사례 연구의 첫 번째 질문을 표시하려면 다음 버튼을 클릭하십시오. 질문에 답하기 전에 왼쪽 창에 있는 버튼을 사용하여 사례 연구의 내용을 탐색하십시오. 이 버튼을 클릭하면 비즈니스 요구 사항, 기존 환경 및 문제 설명과 같은 정보가 표시됩니다. 사례 연구에 모든 정보 탭이 있는 경우 표시되는 정보는 후속 탭에 표시되는 정보와 동일합니다. 질문에 답할 준비가 되면 질문 버튼을 클릭하여 질문으로 돌아갑니다.
개요
뉴욕, 맨체스터, 싱가포르 및 멜버른에 사무실이 있는 글로벌 미디어 회사인 Graphics Design Institute의 데이터 엔지니어링 솔루션을 개발합니다.
뉴욕 사무실은 엄청난 양의 고객 데이터를 저장하는 SQL Server 데이터베이스를 호스팅합니다. 이 회사는 또한 뉴욕 사무실에 있는 물리적 서버에 수백만 개의 이미지를 저장합니다. 매일 2TB 이상의 이미지 데이터가 추가됩니다. 이미지는 고객 장치에서 뉴욕의 서버로 전송됩니다.
이 서버에 많은 이미지가 정리되지 않은 방식으로 배치되어 편집자가 이미지를 검색하기 어렵습니다. 이미지에는 자동으로 개체 및 색상 태그가 생성되어야 합니다. 태그는 문서 데이터베이스에 저장되어야 하며 SQL에서 쿼리해야 합니다.
고객 데이터를 저장, 변환 및 시각화할 수 있는 솔루션을 설계하도록 고용되었습니다.
요구 사항
사업
회사는 다음과 같은 비즈니스 요구 사항을 식별합니다.
* 모든 이미지와 고객 데이터를 클라우드 스토리지로 옮기고 온프레미스 서버를 제거해야 합니다.
* 고객 데이터 변환을 위한 분석 처리 솔루션을 개발해야 합니다.
* 이미지 개체 및 컬러 태깅 솔루션을 개발해야 합니다.
* 자본 지출을 최소화해야 합니다.
* 클라우드 리소스 비용을 최소화해야 합니다.
전문인
솔루션에는 다음과 같은 기술 요구 사항이 있습니다.
* 태깅 데이터는 뉴욕 사무실 위치에서 클라우드로 업로드해야 합니다.
* 태깅 데이터는 회사 사무실 위치와 지리적으로 가까운 지역에 복제해야 합니다.
* 이미지 데이터는 최소 비용으로 단일 데이터 저장소에 저장해야 합니다.
* 고객 데이터는 관리형 Spark 클러스터를 사용하여 분석해야 합니다.
* 변환된 고객 데이터를 시각화하려면 Power BI를 사용해야 합니다.
* 재해 복구가 필요한 경우를 대비하여 모든 데이터를 백업해야 합니다.
보안 및 최적화
모든 클라우드 데이터는 저장 및 전송 중에 암호화되어야 합니다. 솔루션은 다음을 지원해야 합니다.
* 고객 데이터의 병렬 처리
* 하이퍼스케일 이미지 저장
* 처리된 이미지 데이터의 글로벌 지역 데이터 복제
데이터 처리 솔루션 설계
테스트렛 3
사례 연구
이것은 사례 연구입니다. 사례 연구는 별도로 시간이 지정되지 않습니다. 각 사례를 완료하고 싶은 만큼 시험 시간을 사용할 수 있습니다. 그러나 이 시험에 추가 사례 연구 및 섹션이 있을 수 있습니다. 주어진 시간 내에 이 시험에 포함된 모든 문제를 완료할 수 있도록 시간을 관리해야 합니다.
사례 연구에 포함된 질문에 답하려면 사례 연구에 제공된 정보를 참조해야 합니다. 사례 연구에는 사례 연구에 설명된 시나리오에 대한 추가 정보를 제공하는 전시 및 기타 리소스가 포함될 수 있습니다. 각 질문은 이 사례 연구의 다른 질문과 독립적입니다.
이 사례 연구가 끝나면 검토 화면이 나타납니다. 이 화면에서 답을 검토하고 시험의 다음 섹션으로 이동하기 전에 변경할 수 있습니다. 새 섹션을 시작한 후에는 이 섹션으로 돌아갈 수 없습니다.
사례 연구를 시작하려면
이 사례 연구의 첫 번째 질문을 표시하려면 다음 버튼을 클릭하십시오. 질문에 답하기 전에 왼쪽 창에 있는 버튼을 사용하여 사례 연구의 내용을 탐색하십시오. 이 버튼을 클릭하면 비즈니스 요구 사항, 기존 환경 및 문제 설명과 같은 정보가 표시됩니다. 사례 연구에 모든 정보 탭이 있는 경우 표시되는 정보는 후속 탭에 표시되는 정보와 동일합니다. 질문에 답할 준비가 되면 질문 버튼을 클릭하여 질문으로 돌아갑니다.
배경
현재 환경
회사에는 다음과 같은 가상 머신(VM)이 있습니다.
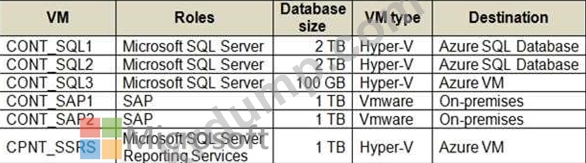
요구 사항
저장 및 처리
Blob에 저장된 데이터의 파일 시스템 보기를 사용할 수 있어야 합니다.
Contoso가 Blob 저장소를 통해 DB FS 파일 시스템 계층을 사용할 수 있도록 하는 아키텍처를 빌드해야 합니다. 아키텍처는 데이터 파일, 라이브러리 및 이미지를 지원해야 합니다. 또한 실행할 수 있는 명령, 시각화 및 노트북과 같은 설명 텍스트가 포함된 문서에 웹 기반 인터페이스를 제공해야 합니다.
CONT_SQL3에는 35000 IOPS의 초기 스케일이 필요합니다.
CONT_SQL1 및 CONT_SQL2는 vCore 모델을 사용해야 하며 복제본을 포함해야 합니다. 솔루션은 8000 IOPS를 지원해야 합니다.
스토리지는 데이터베이스 OLTP 워크로드에 최적화된 스토리지로 구성되어야 합니다.
이주
* 컴퓨팅 및 스토리지 리소스를 독립적으로 확장할 수 있어야 합니다.
* 모든 SQL Server 워크로드를 Azure로 마이그레이션해야 합니다. 온프레미스 환경에서 관련 머신을 식별하고 디스크 크기 데이터 사용 정보를 가져와야 합니다.
* SQL Server의 데이터에는 영역 중복 저장소가 포함되어야 합니다.
* Azure 퍼블릭 클라우드에서 실행되는 구성 요소와 상호 작용하는 동안 앱 구성 요소가 온-프레미스에 상주할 수 있는지 확인해야 합니다.
* SAP 데이터는 온프레미스에 남아 있어야 합니다.
* ASR(Azure Site Recovery) 결과에는 머신별 데이터가 포함되어야 합니다.
비즈니스 요구 사항
* 지역 재해 복구 토폴로지를 설계해야 합니다.
* 데이터베이스 백업은 규제 목적이 있으며 7년 동안 보관해야 합니다.
* CONT_SQL1은 데이터 분석을 위해 ETL 작업이 필요한 고객 판매 데이터를 저장합니다. SQL에서 데이터를 읽고 ETL을 수행하고 Power BI로 출력하는 솔루션이 필요합니다. 솔루션은 비용을 최소화하기 위해 관리형 클러스터를 사용해야 합니다. 물류를 최적화하기 위해 Contoso는 고객 판매 데이터를 분석하여 특정 제품이 연중 특정 시간에 연결되어 있는지 확인해야 합니다.
* 고객 판매 데이터에 대한 분석 솔루션은 지역 정전 시 사용할 수 있어야 합니다.
보안 및 감사
* Contoso를 사용하려면 모든 회사 컴퓨터에서 Windows 방화벽을 사용하도록 설정해야 합니다.
* Azure 서버는 다른 Contoso Azure 서버를 ping할 수 있어야 합니다.
* 직원 PII는 메모리, 이동 중 및 정지 상태에서 암호화되어야 합니다. SQL Server로 암호화된 모든 데이터는 암호화된 데이터에 대한 같음 검색, 그룹화, 인덱싱 및 조인을 지원해야 합니다.
* 키는 하드웨어 보안 모듈(HSM)을 사용하여 보호되어야 합니다.
* CONT_SQL3은 기본 포트를 통해 통신해서는 안 됩니다.
비용
* 모든 솔루션은 비용과 리소스를 최소화해야 합니다.
* 조직은 예상치 못한 요금 청구를 원하지 않습니다.
* 데이터 엔지니어는 300 DWU를 사용하도록 SQL Data Warehouse 컴퓨팅 리소스를 설정해야 합니다.
* CONT_SQL2는 사용량이 많지 않은 시간에는 완전히 활용되지 않습니다. 사용량이 많지 않은 시간에 리소스 비용을 최소화해야 합니다.
DP-201 문제 25
어떤 스토리지 솔루션을 사용해야 합니까?
오답:
A: SQL Database 탄력적 풀은 다양하고 예측할 수 없는 사용 요구 사항이 있는 여러 데이터베이스를 관리하고 확장하기 위한 간단하고 비용 효율적인 솔루션입니다. 탄력적 풀의 데이터베이스는 단일 Azure SQL Database 서버에 있으며 정해진 가격으로 정해진 수의 리소스를 공유합니다. Azure SQL Database의 탄력적 풀을 사용하면 SaaS 개발자가 지정된 예산 내에서 데이터베이스 그룹의 가격 성능을 최적화하는 동시에 각 데이터베이스에 대한 성능 탄력성을 제공할 수 있습니다.
B: SQL Data Warehouse 대신 싱글톤 선택이 많은 운영(OLTP) 워크로드에 대한 다른 옵션을 고려하십시오.
참조:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-service-tier-hyperscale-faq
- 최근 업로드
- 107Snowflake.ADA-C02.v2026-06-08.q23
- 108Microsoft.SC-300-KR.v2026-06-08.q173
- 109Microsoft.DP-300-KR.v2026-06-08.q157
- 111Microsoft.MS-102-KR.v2026-06-08.q240
- 109Microsoft.DP-300-KR.v2026-06-08.q176
- 108Microsoft.SC-100-KR.v2026-06-08.q115
- 120TheBerylInstitute.CPXP.v2026-06-06.q56
- 176ACAMS.CAMS7-KR.v2026-06-05.q213
- 181PaloAltoNetworks.XSIAM-Analyst.v2026-06-04.q72
- 152NLN.NEX.v2026-06-04.q54
PDF 파일 다운로드
메일 주소를 입력하시고 다운로드 하세요. Microsoft.DP-201.v2021-12-28.q193 모의시험 시험자료를 다운 받으세요.