
Professional-Machine-Learning-Engineer 문제 16
You have trained a model on a dataset that required computationally expensive preprocessing operations. You need to execute the same preprocessing at prediction time. You deployed the model on Al Platform for high-throughput online prediction. Which architecture should you use?
Professional-Machine-Learning-Engineer 문제 17
Your organization wants to make its internal shuttle service route more efficient. The shuttles currently stop at all pick-up points across the city every 30 minutes between 7 am and 10 am. The development team has already built an application on Google Kubernetes Engine that requires users to confirm their presence and shuttle station one day in advance. What approach should you take?
Professional-Machine-Learning-Engineer 문제 18
You developed an ML model with Al Platform, and you want to move it to production. You serve a few thousand queries per second and are experiencing latency issues. Incoming requests are served by a load balancer that distributes them across multiple Kubeflow CPU-only pods running on Google Kubernetes Engine (GKE). Your goal is to improve the serving latency without changing the underlying infrastructure. What should you do?
Professional-Machine-Learning-Engineer 문제 19
A credit card company wants to build a credit scoring model to help predict whether a new credit card applicant will default on a credit card payment. The company has collected data from a large number of sources with thousands of raw attributes. Early experiments to train a classification model revealed that many attributes are highly correlated, the large number of features slows down the training speed significantly, and that there are some overfitting issues.
The Data Scientist on this project would like to speed up the model training time without losing a lot of information from the original dataset.
Which feature engineering technique should the Data Scientist use to meet the objectives?
The Data Scientist on this project would like to speed up the model training time without losing a lot of information from the original dataset.
Which feature engineering technique should the Data Scientist use to meet the objectives?
Professional-Machine-Learning-Engineer 문제 20
This graph shows the training and validation loss against the epochs for a neural network.
The network being trained is as follows:
* Two dense layers, one output neuron
* 100 neurons in each layer
* 100 epochs
* Random initialization of weights
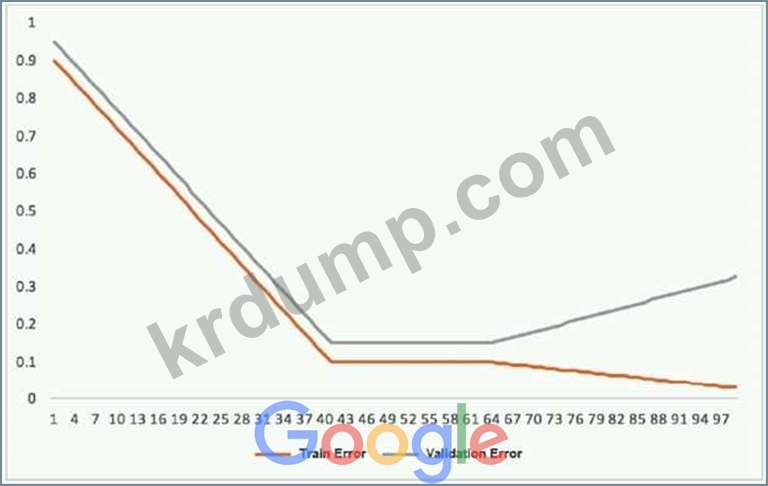
Which technique can be used to improve model performance in terms of accuracy in the validation set?
The network being trained is as follows:
* Two dense layers, one output neuron
* 100 neurons in each layer
* 100 epochs
* Random initialization of weights
Which technique can be used to improve model performance in terms of accuracy in the validation set?